Supervised learning, also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence. It is defined by its use of labeled datasets to train algorithms that to classify data or predict outcomes accurately.
Machine Learning Regression is a technique for investigating the relationship between independent variables or features and a dependent variable or outcome. It’s used as a method for predictive modelling in machine learning, in which an algorithm is used to predict continuous outcomes. You can read more about it here!
In this blog, we will discuss two types of regression problems, Linear Regression, and Non-Linear Regression. For each, we will compare a handful of machine learning models (linear and non-linear models) and present their results on evaluation metrics.
Linear Regression This form of analysis estimates the coefficients of the linear equation, involving one or more independent variables that best predict the value of the dependent variable. Linear regression fits a straight line or surface that minimizes the discrepancies between predicted and actual output values.
We’ll make use of the Seoul Bike Sharing dataset which contains count of public bicycles rented per hour in the Seoul Bike Sharing System, with corresponding weather data and holiday information. The dataset contains weather information (Temperature, Humidity, Windspeed, Visibility, Dewpoint, Solar radiation, Snowfall, Rainfall), the number of bikes rented per hour and date information. A sample of the dataset can be seen below. The aim is to predict the bike count required at each hour for the stable supply of rental bikes.
Code
import pandas as pdimport numpy as npimport warningswarnings.filterwarnings("ignore")df_bike = pd.read_csv("SeoulBikeData.csv")df_bike.head(5)
Date
Rented Bike Count
Hour
Temperature(C)
Humidity(%)
Wind speed (m/s)
Visibility (10m)
Dew point temperature(C)
Solar Radiation (MJ/m2)
Rainfall(mm)
Snowfall (cm)
Seasons
Holiday
Functioning Day
0
01/12/2017
254
0
-5.2
37
2.2
2000
-17.6
0.0
0.0
0.0
Winter
No Holiday
Yes
1
01/12/2017
204
1
-5.5
38
0.8
2000
-17.6
0.0
0.0
0.0
Winter
No Holiday
Yes
2
01/12/2017
173
2
-6.0
39
1.0
2000
-17.7
0.0
0.0
0.0
Winter
No Holiday
Yes
3
01/12/2017
107
3
-6.2
40
0.9
2000
-17.6
0.0
0.0
0.0
Winter
No Holiday
Yes
4
01/12/2017
78
4
-6.0
36
2.3
2000
-18.6
0.0
0.0
0.0
Winter
No Holiday
Yes
It is important to check the dataset for any missing values before it is used for model training and testing.
This dataset seems to have no missing values so we’re good!
Let’s format the dataset to ease data processing down the line. Beginning with breaking down the ‘Date’ into ‘Day’, ‘Month’, and ‘Year’ columns in the dataset.
# Can break the date into date, month, year columns and convert them into integers (from strings) for the purpose of correlation mapdays = [int((df_bike['Date'].iloc[i])[0:2]) for i inrange(len(df_bike))]month = [int((df_bike['Date'].iloc[i])[3:5]) for i inrange(len(df_bike))]year = [int((df_bike['Date'].iloc[i])[6:]) for i inrange(len(df_bike))]df_bike['Day'], df_bike['Month'], df_bike['Year'] = days, month, yeardf_bike.head(5)
Date
Rented Bike Count
Hour
Temperature(C)
Humidity(%)
Wind speed (m/s)
Visibility (10m)
Dew point temperature(C)
Solar Radiation (MJ/m2)
Rainfall(mm)
Snowfall (cm)
Seasons
Holiday
Functioning Day
Day
Month
Year
0
01/12/2017
254
0
-5.2
37
2.2
2000
-17.6
0.0
0.0
0.0
Winter
No Holiday
Yes
1
12
2017
1
01/12/2017
204
1
-5.5
38
0.8
2000
-17.6
0.0
0.0
0.0
Winter
No Holiday
Yes
1
12
2017
2
01/12/2017
173
2
-6.0
39
1.0
2000
-17.7
0.0
0.0
0.0
Winter
No Holiday
Yes
1
12
2017
3
01/12/2017
107
3
-6.2
40
0.9
2000
-17.6
0.0
0.0
0.0
Winter
No Holiday
Yes
1
12
2017
4
01/12/2017
78
4
-6.0
36
2.3
2000
-18.6
0.0
0.0
0.0
Winter
No Holiday
Yes
1
12
2017
Next, we convert string values such as the values in the ‘Seasons’, ‘Functioning Day’, and ‘Holiday’ columns. We are able to do this by mapping the discrete set of string values to a discrete set of integer values.
df1_bike = df_bike.drop(columns = ['Date'])# map unique season to numbers, map holiday to binary, and functioning day to binaryseasons = {}for idx, i inenumerate(df_bike['Seasons'].drop_duplicates()): seasons[i] = idxholiday = {"No Holiday": 0, "Holiday": 1}functioning = {"Yes": 0, "No": 1}df1_bike.Holiday = [holiday[item] for item in df_bike.Holiday]df1_bike.Seasons = [seasons[item] for item in df_bike.Seasons]df1_bike['Functioning Day'] = [functioning[item] for item in df1_bike['Functioning Day'] ]df1_bike.head(3)
Rented Bike Count
Hour
Temperature(C)
Humidity(%)
Wind speed (m/s)
Visibility (10m)
Dew point temperature(C)
Solar Radiation (MJ/m2)
Rainfall(mm)
Snowfall (cm)
Seasons
Holiday
Functioning Day
Day
Month
Year
0
254
0
-5.2
37
2.2
2000
-17.6
0.0
0.0
0.0
0
0
0
1
12
2017
1
204
1
-5.5
38
0.8
2000
-17.6
0.0
0.0
0.0
0
0
0
1
12
2017
2
173
2
-6.0
39
1.0
2000
-17.7
0.0
0.0
0.0
0
0
0
1
12
2017
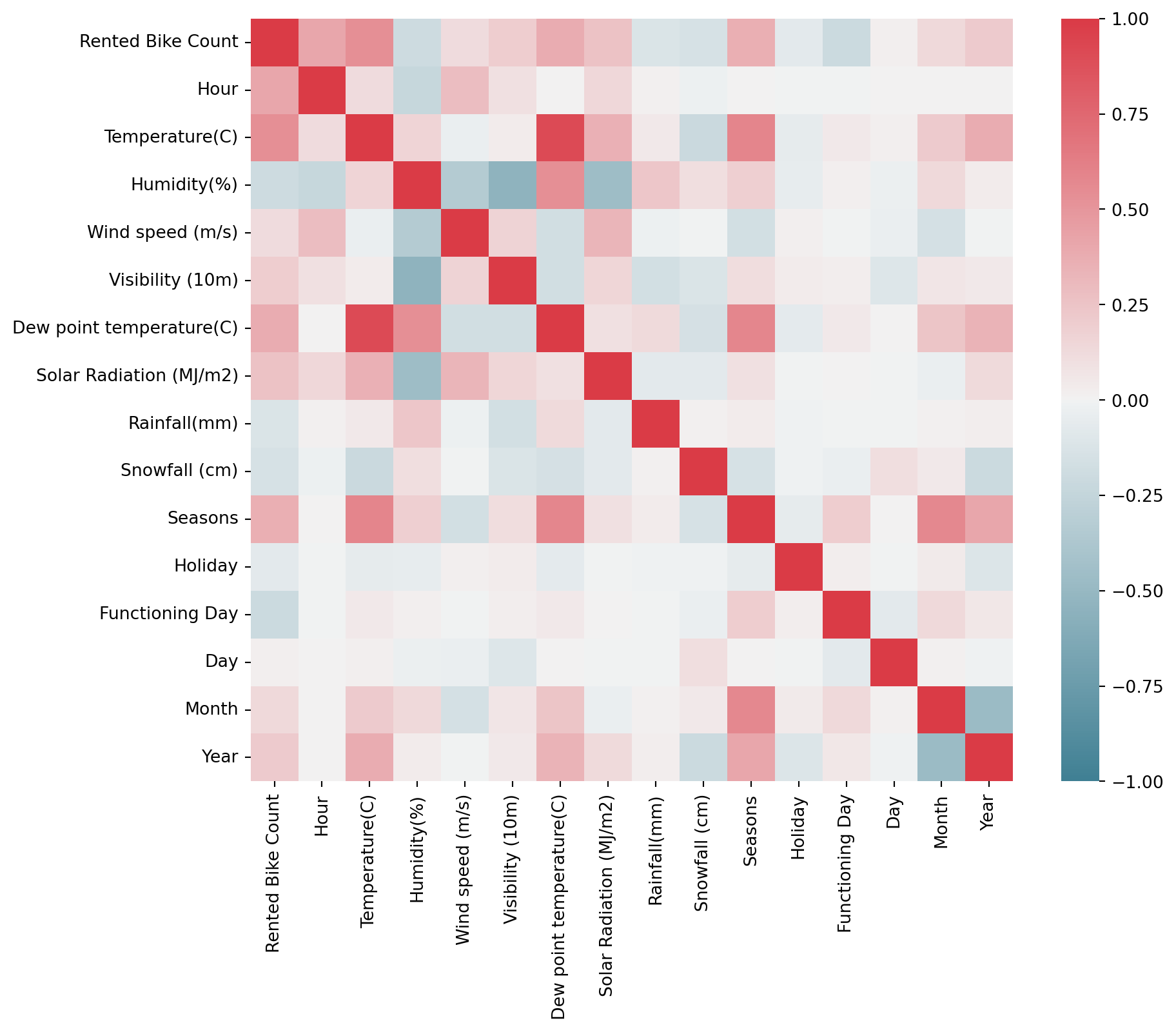
Plotting the correlation matrix to identify the relationship, and the strength of relationship between the features(variables) in the dataset and also understand how strongly they are correlated with the target variable which is the rented bike count.
Code
import seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize=(10, 8))corr = df1_bike.corr()sns.heatmap(corr, cmap=sns.diverging_palette(220, 10, as_cmap=True), vmin=-1.0, vmax=1.0, square=True, ax=ax)
<Axes: >
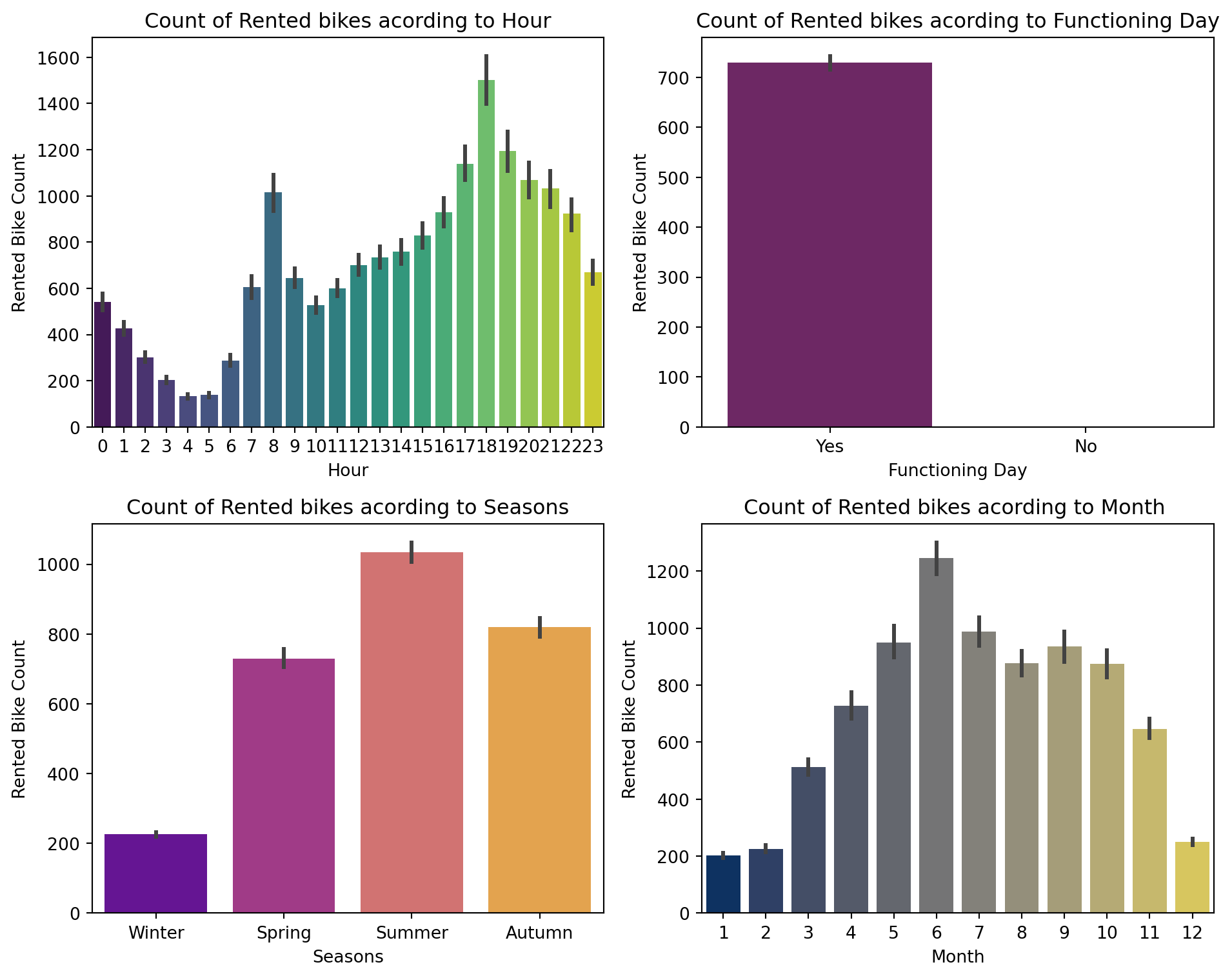
Below, we can plot visualizations to see how each feature (variable) effects the target: Rented Bike Count.
Code
plt.rcParams["figure.autolayout"] =Truefig, ax = plt.subplots(2, 2, figsize=(10, 8));# hour vs bike countsns.barplot(data=df1_bike,x='Hour',y='Rented Bike Count',ax=ax[0][0], palette='viridis');ax[0][0].set(title='Count of Rented bikes acording to Hour');# Functioning vs bike countsns.barplot(data=df1_bike,x='Functioning Day',y='Rented Bike Count',ax=ax[0][1], palette='inferno');ax[0][1].set(title='Count of Rented bikes acording to Functioning Day');ax[0][1].set_xticklabels(['Yes', 'No'])# season vs bike countsns.barplot(data=df1_bike,x='Seasons', y='Rented Bike Count',ax=ax[1][0], palette='plasma');ax[1][0].set(title='Count of Rented bikes acording to Seasons');ax[1][0].set_xticklabels(['Winter', 'Spring', 'Summer', 'Autumn'])# month vs bike countsns.barplot(data=df1_bike,x='Month',y='Rented Bike Count',ax=ax[1][1], palette='cividis');ax[1][1].set(title='Count of Rented bikes acording to Month ');plt.show()
Code
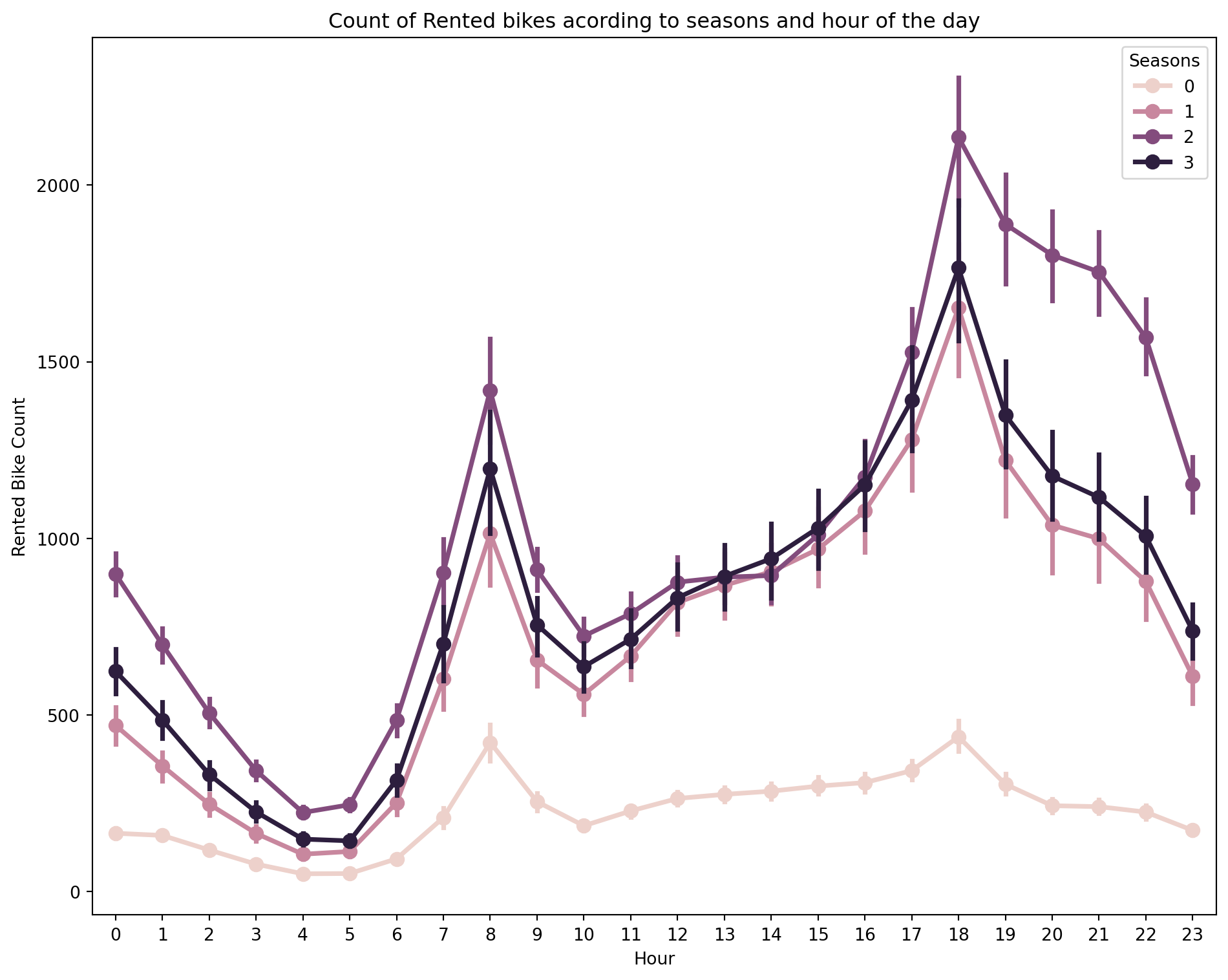
fig,ax=plt.subplots(figsize=(10,8))sns.pointplot(data=df1_bike,x='Hour',y='Rented Bike Count',hue='Seasons',ax=ax);ax.set(title='Count of Rented bikes acording to seasons and hour of the day');
Code
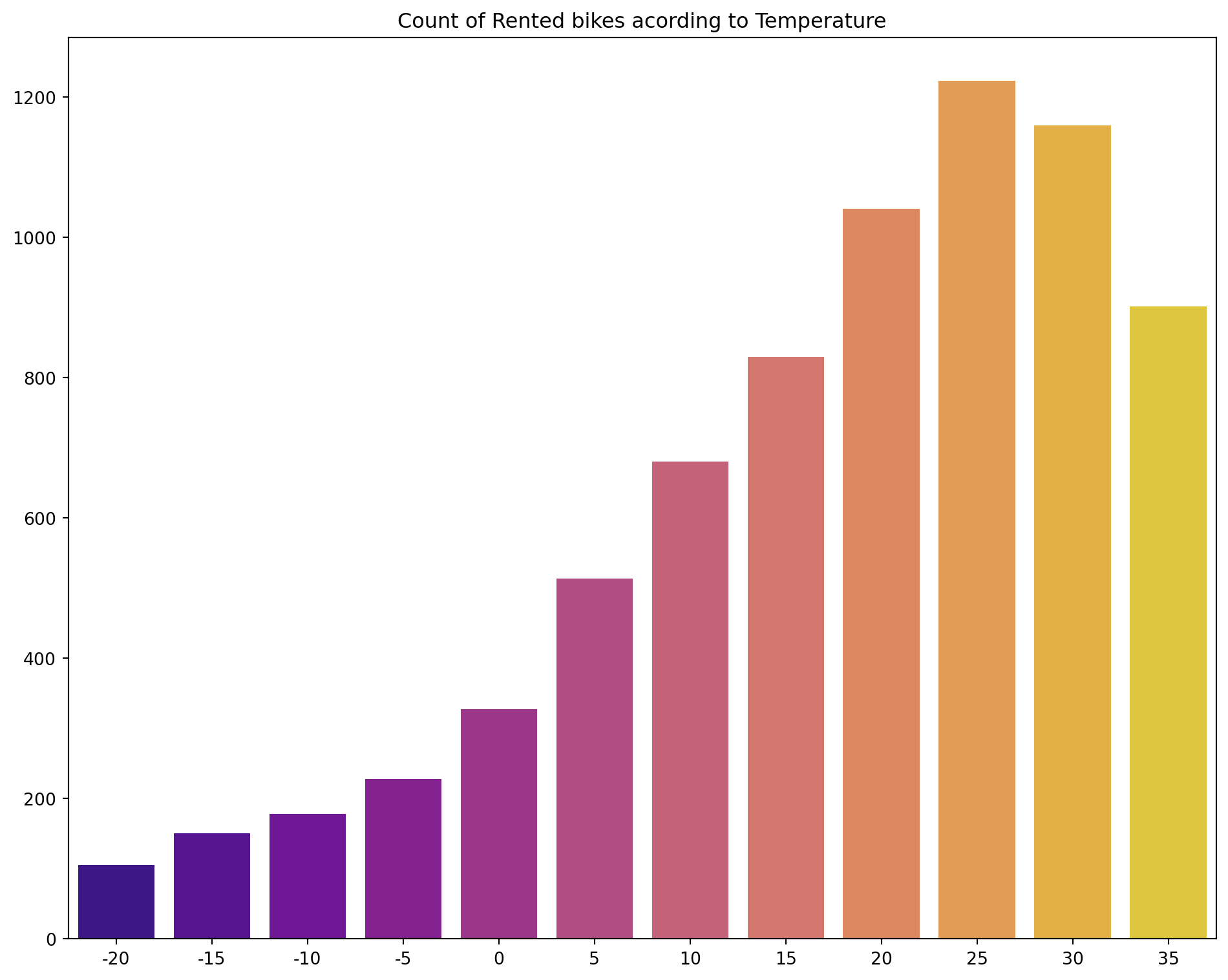
fig, ax = plt.subplots(figsize=(10, 8));# temperature vs bike count# Convert temperature in groups of 5C and average the rented bike counts for that range (rounding to 5s)temp_min, temp_max =round(min(df1_bike['Temperature(C)'])/5)*5, round(max(df1_bike['Temperature(C)'])/5)*5dict_temp = {}for i inrange(temp_min, temp_max, 5):# Filter rows based on the temperature interval filtered_df = df1_bike[(df1_bike['Temperature(C)'] >= i) & (df1_bike['Temperature(C)'] < i+5)] dict_temp[i] = filtered_df['Rented Bike Count'].mean()# print(dict_temp)# print(temp_max, temp_min)sns.barplot(data=dict_temp,ax=ax, palette='plasma');ax.set(title='Count of Rented bikes acording to Temperature');# plt.show()
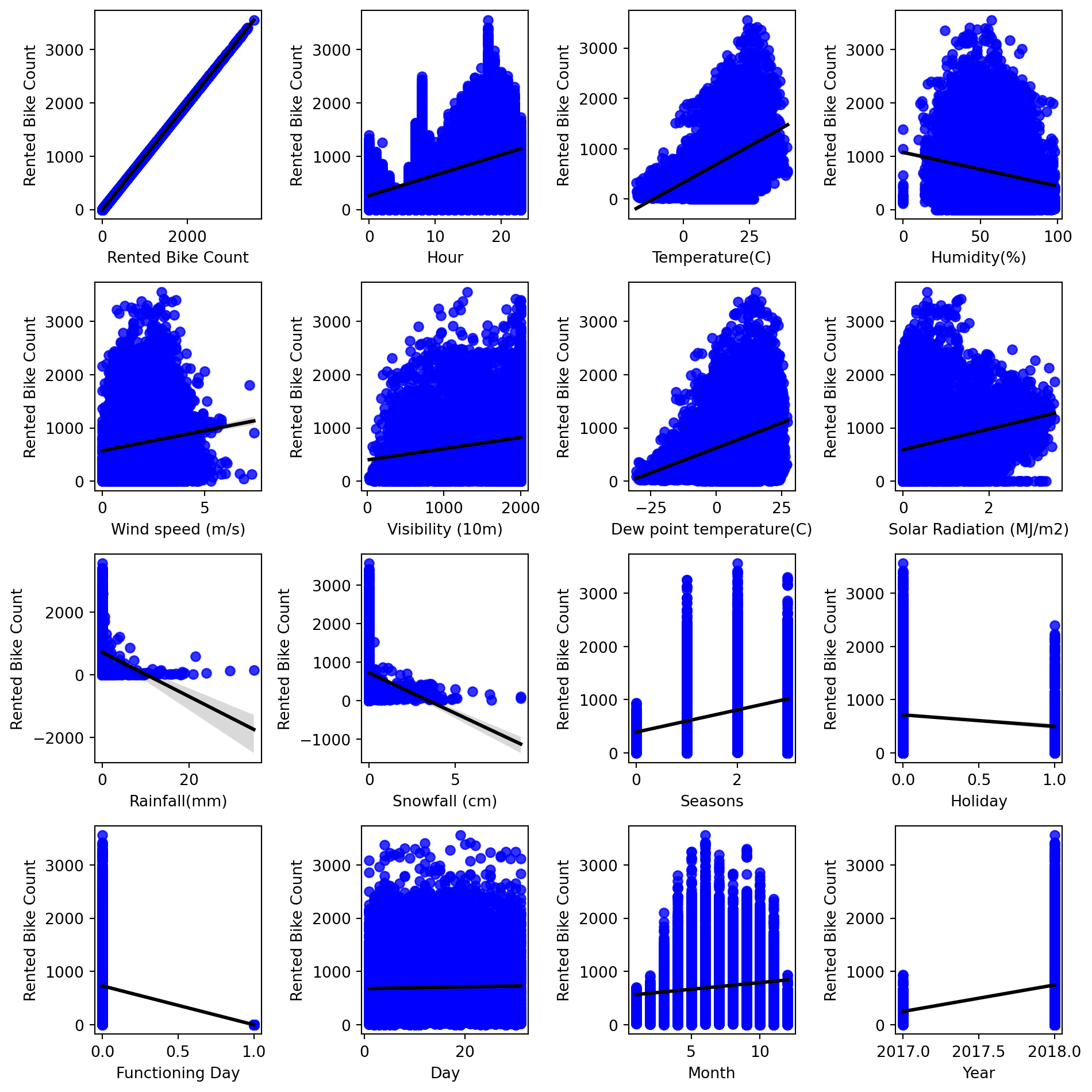
Printing the regression plot (Dependent Features vs Target Varibale).
fig,ax=plt.subplots(4, 4, figsize=(10,10)) # since we know there are 16 featuresfor idx, col inenumerate(df1_bike.columns): sns.regplot(x=df1_bike[col],y=df1_bike['Rented Bike Count'],scatter_kws={"color": 'blue'}, line_kws={"color": "black"}, ax=ax[idx//4][idx%4])
To train and evaluate the machine learning models we need to split the dataset appropriately into the training and testing datasets. Hence, we perform an 80-20 train-test split here.
Code
from sklearn.model_selection import train_test_splity = df1_bike['Rented Bike Count']X = (df1_bike.drop(columns = ['Rented Bike Count'])).to_numpy()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
The following are the models used for estimating the number of bikes rented given other data. The code implementations for each can be found in the scikit-learn library (linked for each model), and the model paramters used are default parameters. 1. Linear regression modelLinear regression is a simple yet powerful algorithm that models the relationship between the input features and the target variable by fitting a linear equation to the observed data. The main algorithm involves finding the coefficients that minimize the sum of squared differences between the predicted and actual values. This is typically achieved using the Ordinary Least Squares (OLS) method, aiming to optimize the line’s parameters to best represent the data points.
Support Vector Machine (Regressor) In regression tasks, Support Vector Machines (SVM) aim to find the hyperplane that best represents the relationship between the input features and the target variable. The primary algorithm involves identifying the support vectors and determining the optimal hyperplane to maximize the margin while minimizing the error. SVM uses a loss function that penalizes deviations from the regression line, and the algorithm seeks to find the coefficients that minimize this loss.
Ridge RegressionRidge Regression is an extension of linear regression that introduces a regularization term to prevent overfitting. The main algorithm involves adding a penalty term to the linear regression objective function, which is proportional to the square of the L2 norm of the coefficients. This regularization term helps stabilize the model by shrinking the coefficients, particularly useful when dealing with multicollinearity.
Lasso RegressionLasso Regression, similar to Ridge Regression, introduces regularization to linear regression. The main algorithm incorporates a penalty term, but in this case, it is proportional to the absolute value of the L1 norm of the coefficients. Lasso regression is effective for feature selection as it tends to produce sparse coefficient vectors, driving some coefficients to exactly zero.
Gradient Boosting RegressorGradient Boosting Regressor is an ensemble learning method that builds a series of decision trees sequentially. The main algorithm involves fitting a weak learner (usually a shallow decision tree) to the residuals of the previous trees. The predictions of individual trees are combined to improve overall accuracy. The algorithm minimizes a loss function by adjusting the weights of the weak learners.
Random Forest RegressorRandom Forest Regressor is an ensemble learning method that constructs multiple decision trees during training. The main algorithm involves training each tree on a random subset of the training data and features. The predictions of individual trees are then averaged or aggregated to reduce overfitting and improve generalization. Random Forest leverages the diversity among trees for robust predictions.
Decision Tree RegressorDecision Tree Regressor models the relationship between input features and the target variable by recursively splitting the data based on feature thresholds. The main algorithm involves selecting the best split at each node to minimize the variance of the target variable. Decision trees are constructed until a stopping criterion is met, creating a tree structure that facilitates predictive modeling.
The model is fit on the training data, and predicted for the testing data. Regression models are commonly evaluated on the following metrics: 1. Mean Squared Error (MSE): MSE calculates the average squared difference between the predicted and actual values, providing a measure of the model’s precision. $ = _{i=1}^{n} (y_i - _i)^2$
Root Mean Squared Error (RMSE): RMSE is the square root of MSE and represents the average magnitude of the residuals in the same units as the target variable. $ = $
Mean Absolute Error (MAE): MAE calculates the average absolute difference between the predicted and actual values, providing a measure of the model’s accuracy. $ = _{i=1}^{n} |y_i - _i|$
R2 Score: R2 Score, or the coefficient of determination, measures the proportion of the variance in the dependent variable that is predictable from the independent variables. $ R^2 = 1 - where is the sum of squared residuals, and is the total sum of squares.$
Explained Variance Score: The Explained Variance Score measures the proportion by which the model’s variance is reduced compared to a simple mean baseline. $ = 1 - where where y is the actual values and is the predicted values$
y_preds = [] # list of model predictionsmodel_scores = [] # list of model scores based on the evaluation metrics definedfor model in models: reg = model reg.fit(X_train, y_train) y_pred = reg.predict(X_test) y_preds.append(y_pred) mse = mean_squared_error(y_test.values, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test.values, y_pred) r2 = r2_score(y_test.values, y_pred) evs = explained_variance_score(y_test.values, y_pred) model_scores.append([mse, rmse, mae, r2, evs])
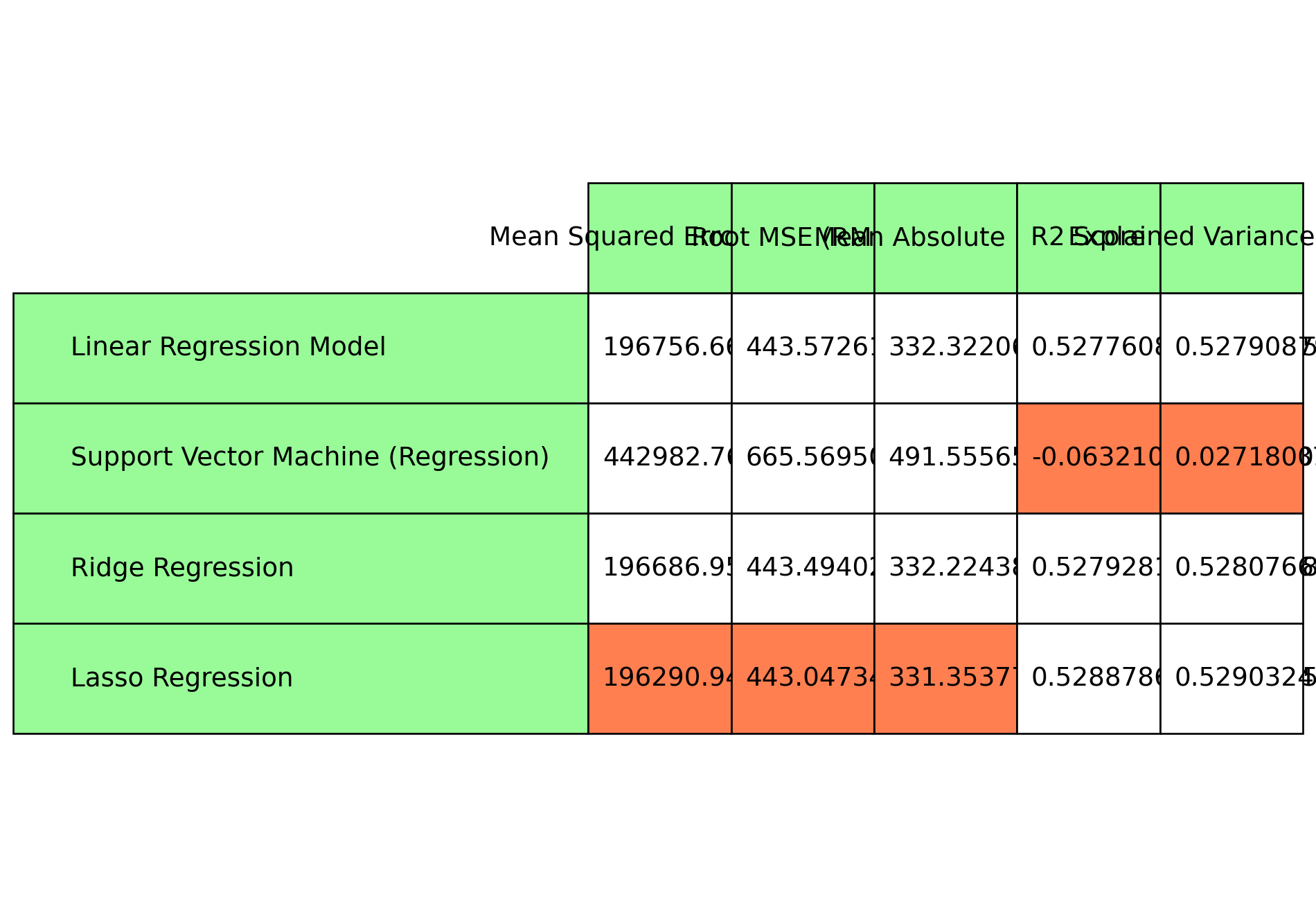
Let us visualize the outputs of the linear models ‘Linear Regression Model’,‘Support Vector Machine (Regression)’, ‘Ridge Regression’, and ‘Lasso Regression’. and evaluate the results.
Code
plt.rcParams["figure.figsize"] = [10,7]plt.rcParams["figure.autolayout"] =Truefig, axs = plt.subplots(1, 1)axs.axis('tight')axs.axis('off')table1 = axs.table(cellText=model_scores[0:4], cellLoc ='left', rowLabels = model_names[0:4], rowColours= ["palegreen"] *10, colLabels=evaluation_metrics, colColours= ["palegreen"] *10, loc='center')# Highlight cells with minimum value in each columnfor col_idx, metric inenumerate(evaluation_metrics): col_values = [row[col_idx] for row in model_scores[0:4]] min_value_idx = col_values.index(min(col_values))# Highlight the cell with minimum value in coral color table1[min_value_idx +1, col_idx].set_facecolor("coral")table1.auto_set_font_size(False)table1.set_fontsize(14)table1.scale(1, 4)fig.tight_layout()plt.show()
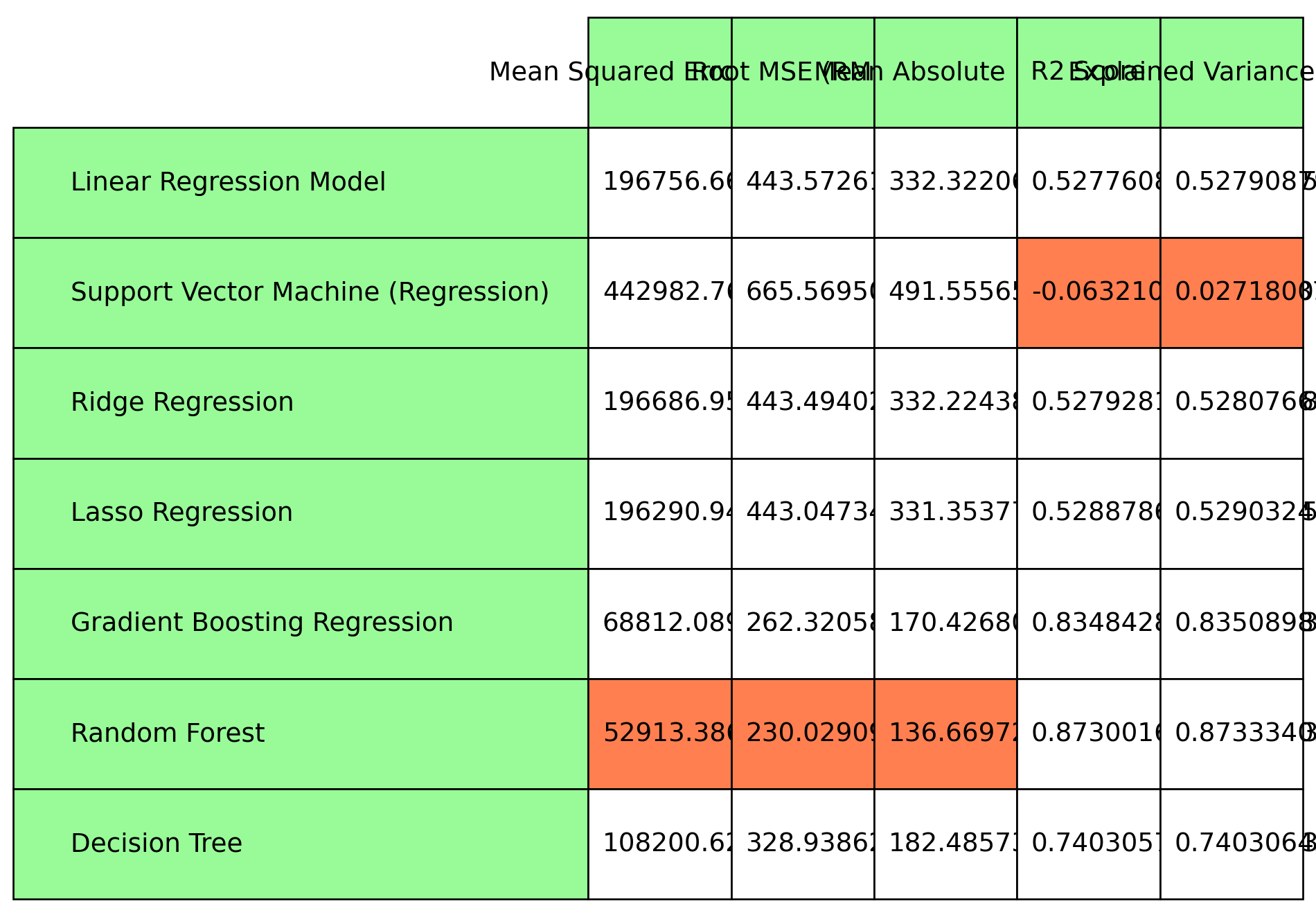
Now, let us compare the performance of the linear models against non linear models on Linear Regression.
Code
plt.rcParams["figure.figsize"] = [10, 7]plt.rcParams["figure.autolayout"] =Truefig, axs = plt.subplots(1, 1)axs.axis('tight')axs.axis('off')table2 = axs.table(cellText=model_scores, cellLoc ='left', rowLabels = model_names, rowColours= ["palegreen"] *10, colLabels=evaluation_metrics, colColours= ["palegreen"] *10, loc='center')# Highlight cells with minimum value in each columnfor col_idx, metric inenumerate(evaluation_metrics): col_values = [row[col_idx] for row in model_scores] min_value_idx = col_values.index(min(col_values))# Highlight the cell with minimum value in coral color table2[min_value_idx +1, col_idx].set_facecolor("coral")table2.auto_set_font_size(False)table2.set_fontsize(14)table2.scale(1, 4)fig.tight_layout()plt.show()
As we can see, non-linear models, due to their complex structure and abilty to map and analyze/learn from complex data, perform better on this task. However, it is not always that non-linear models are better than linear models since we must keep in mind the computational expense and efficiency of a model for a task, as well as the bias-variance tradeoff which again, is dependent not only on the model but also on the dataset/application at hand.
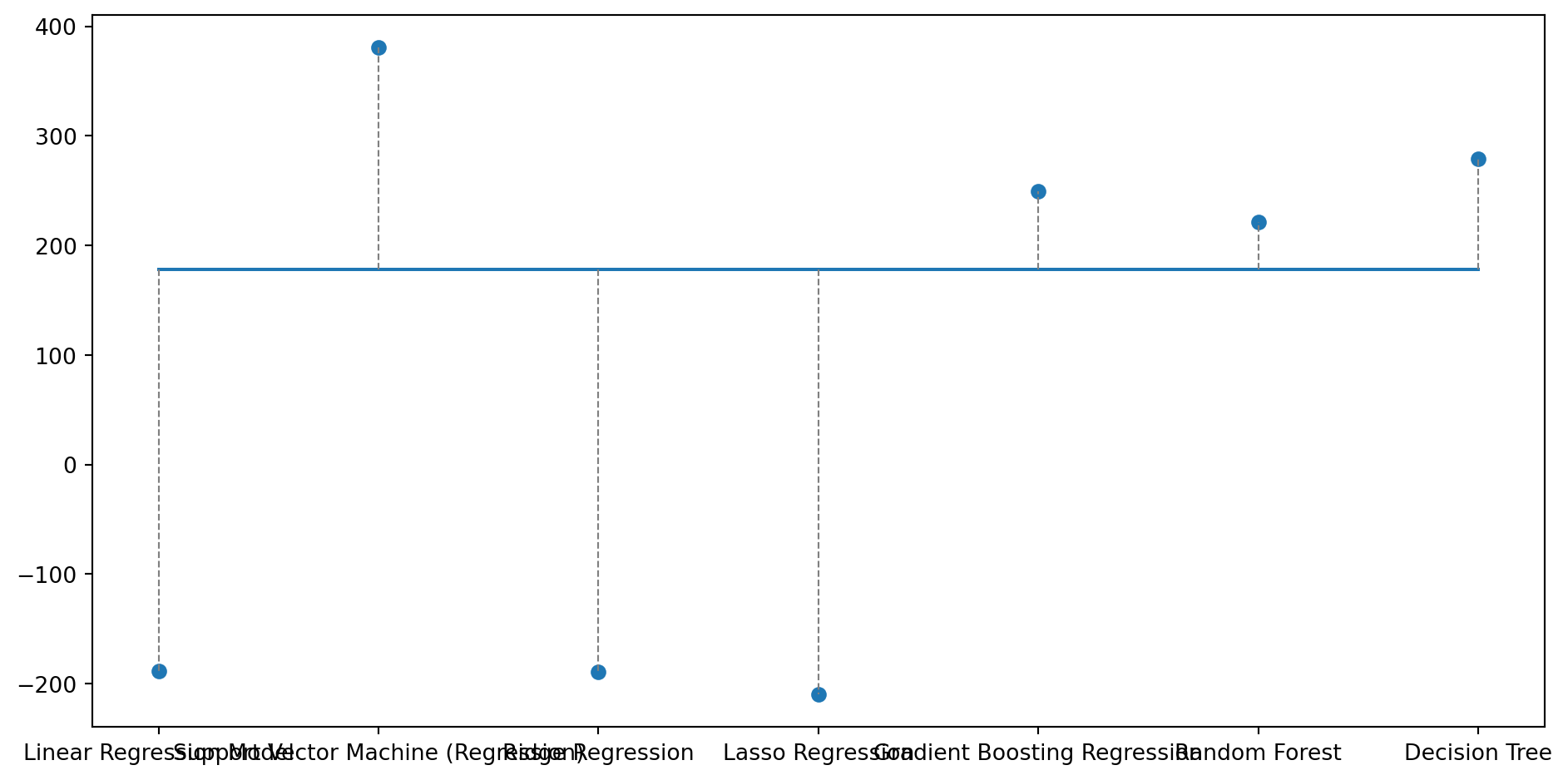
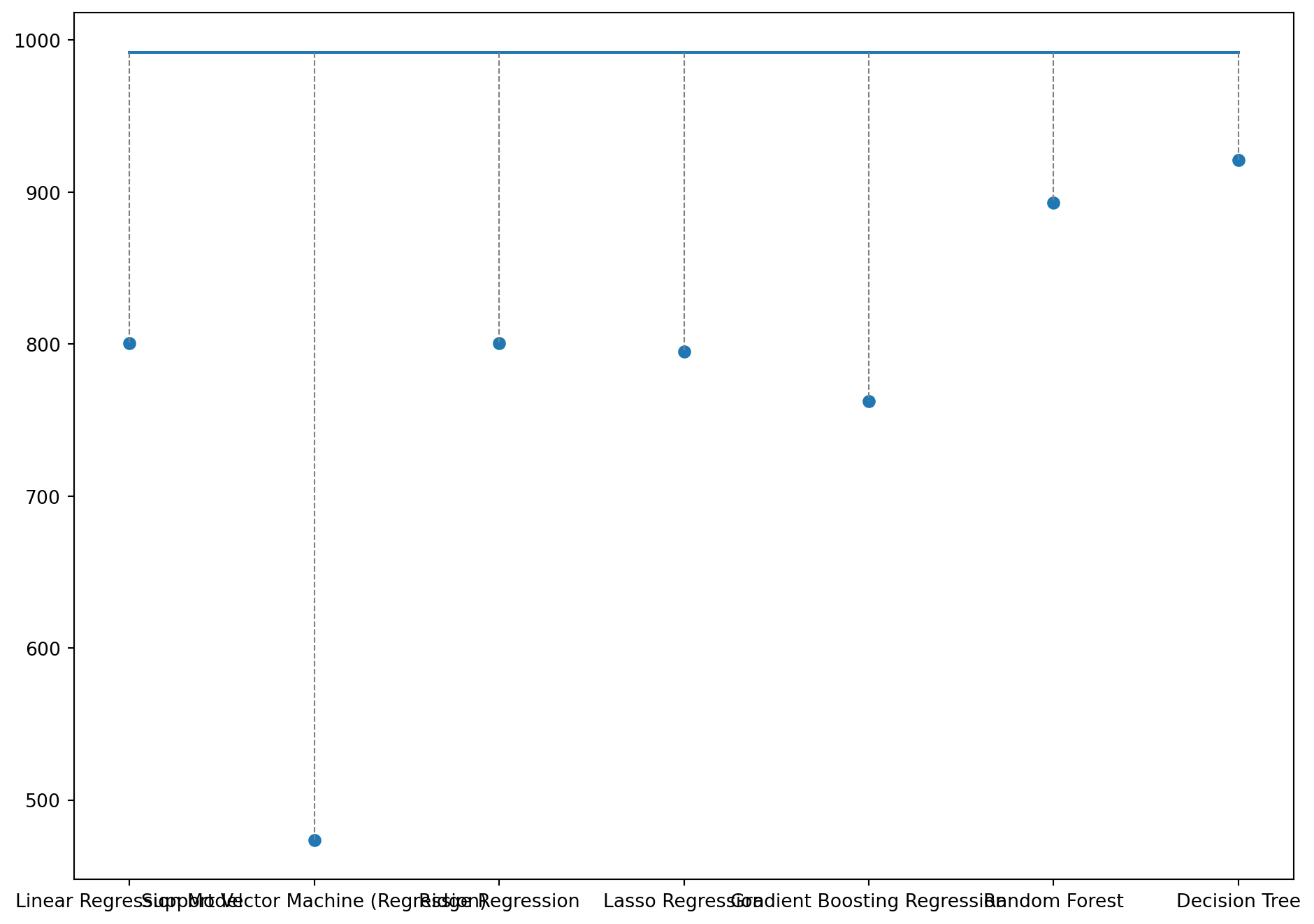
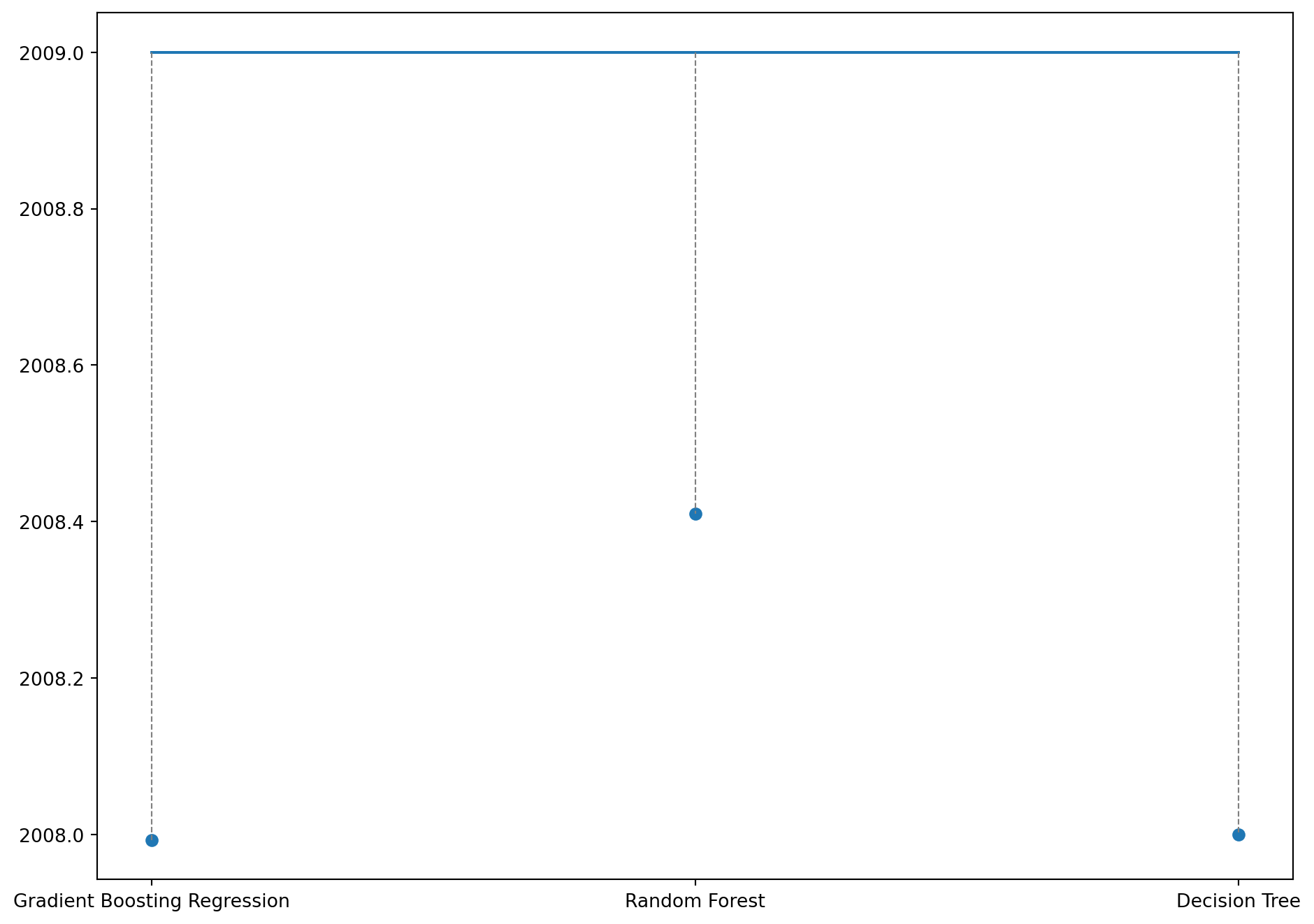
Analysing the difference between the actual and predicted values for the regression task by each model on 3 randomly chosen data points.
Code
# printing how far the predicted value is to the actual value for a random row in Ximport randomfig, ax = plt.subplots(figsize=(10, 5));length =len(model_names)for i inrange(3): idx = random.randint(0,len(y_test)-1) plt.plot(range(length), [(y_test.values)[idx]]*length, label='True Value'); plt.scatter(range(length), [y_preds[q][idx] for q inrange(length)], label='Predicted Values');for j inrange(length): plt.plot([j, j], [(y_test.values)[idx], y_preds[j][idx]], color='gray', linestyle='--', linewidth=0.8) plt.xticks(range(length), model_names) plt.tight_layout() plt.show()
Non Linear RegressionNonlinear regression is a statistical technique that helps describe nonlinear relationships in experimental data. Nonlinear regression models are generally assumed to be parametric, where the model is described as a nonlinear equation. Typically machine learning methods are used for non-parametric nonlinear regression. Parametric nonlinear regression models the dependent variable (also called the response) as a function of a combination of nonlinear parameters and one or more independent variables (called predictors). The model can be univariate (single response variable) or multivariate (multiple response variables).The parameters can take the form of an exponential, trigonometric, power, or any other nonlinear function.
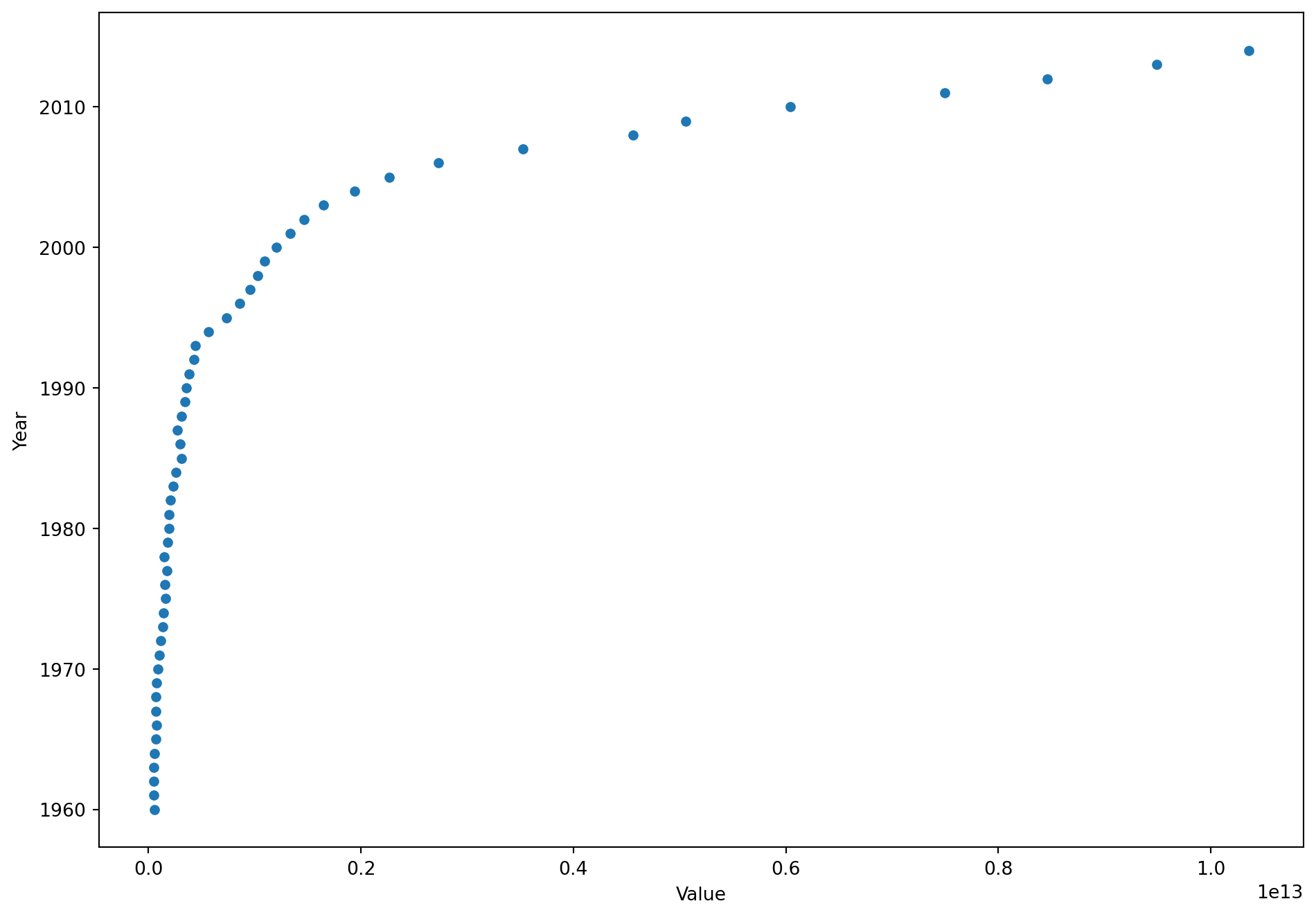
The non-linear dataset models China’s GDP value for each year from 1960-2014. A sample of the dataset and the dataset visualization can be seen below.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 55 entries, 0 to 54
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year 55 non-null int64
1 Value 55 non-null float64
dtypes: float64(1), int64(1)
memory usage: 1008.0 bytes
None
Year 0
Value 0
dtype: int64
Year
Value
0
1960
5.918412e+10
1
1961
4.955705e+10
2
1962
4.668518e+10
3
1963
5.009730e+10
4
1964
5.906225e+10
# plot Year vs GDP_valuesns.scatterplot(data=df_gdp, x ='Value', y ='Year');plt.show()
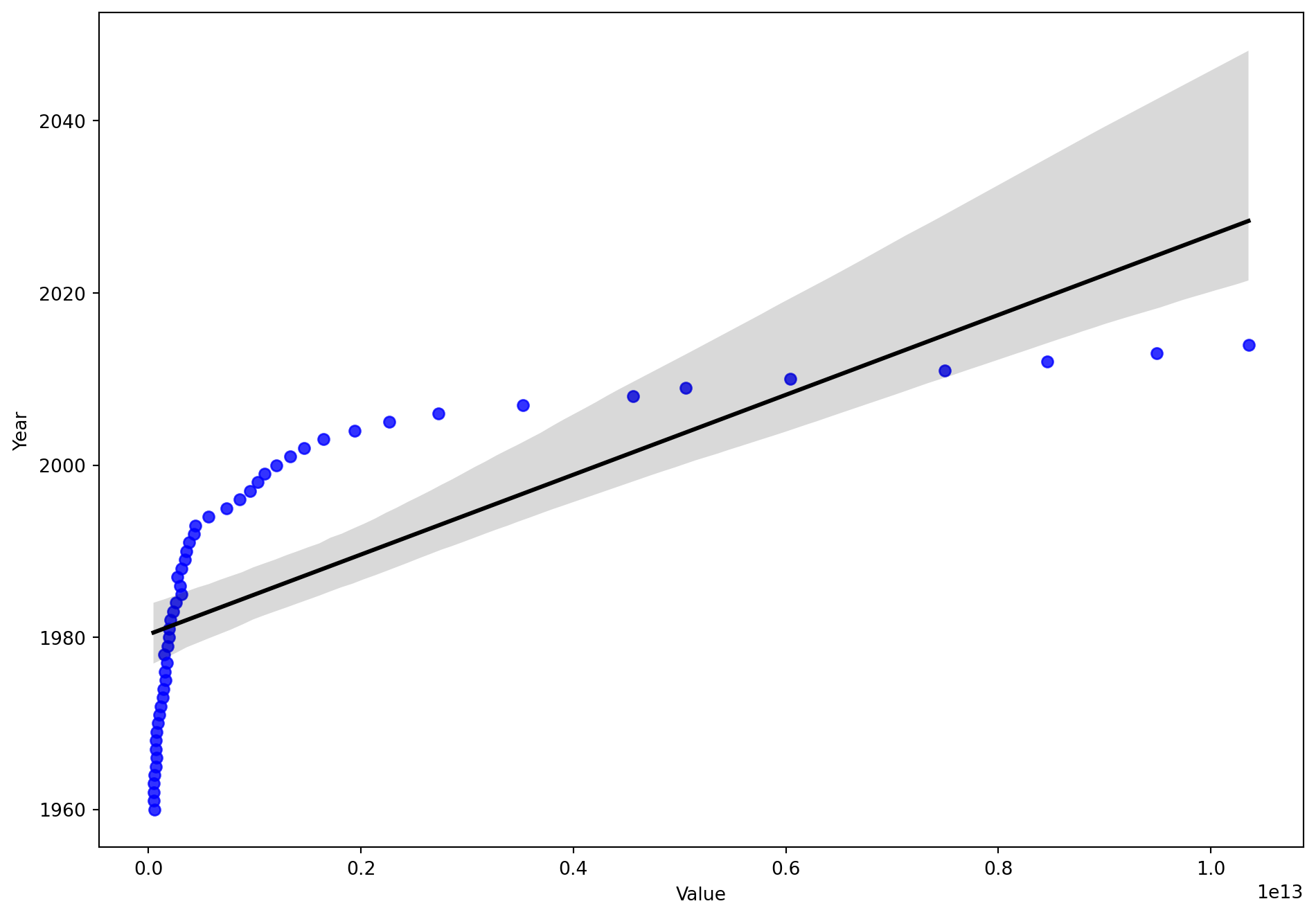
We try to apply a regression line plot for the data. We see that the regression line is not able to accurately capture a linear relationship due to the non-linear relationship between the variables.
# Regression line plotsns.regplot(x=df_gdp['Value'],y=df_gdp['Year'],scatter_kws={"color": 'blue'}, line_kws={"color": "black"})plt.show()
Splitting the dataset into 80-20 training-testing set to train and evaluate the aforementioned models.
Code
from sklearn.model_selection import train_test_splity = df_gdp['Year']X = (df_gdp.drop(columns = ['Year'])).to_numpy()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
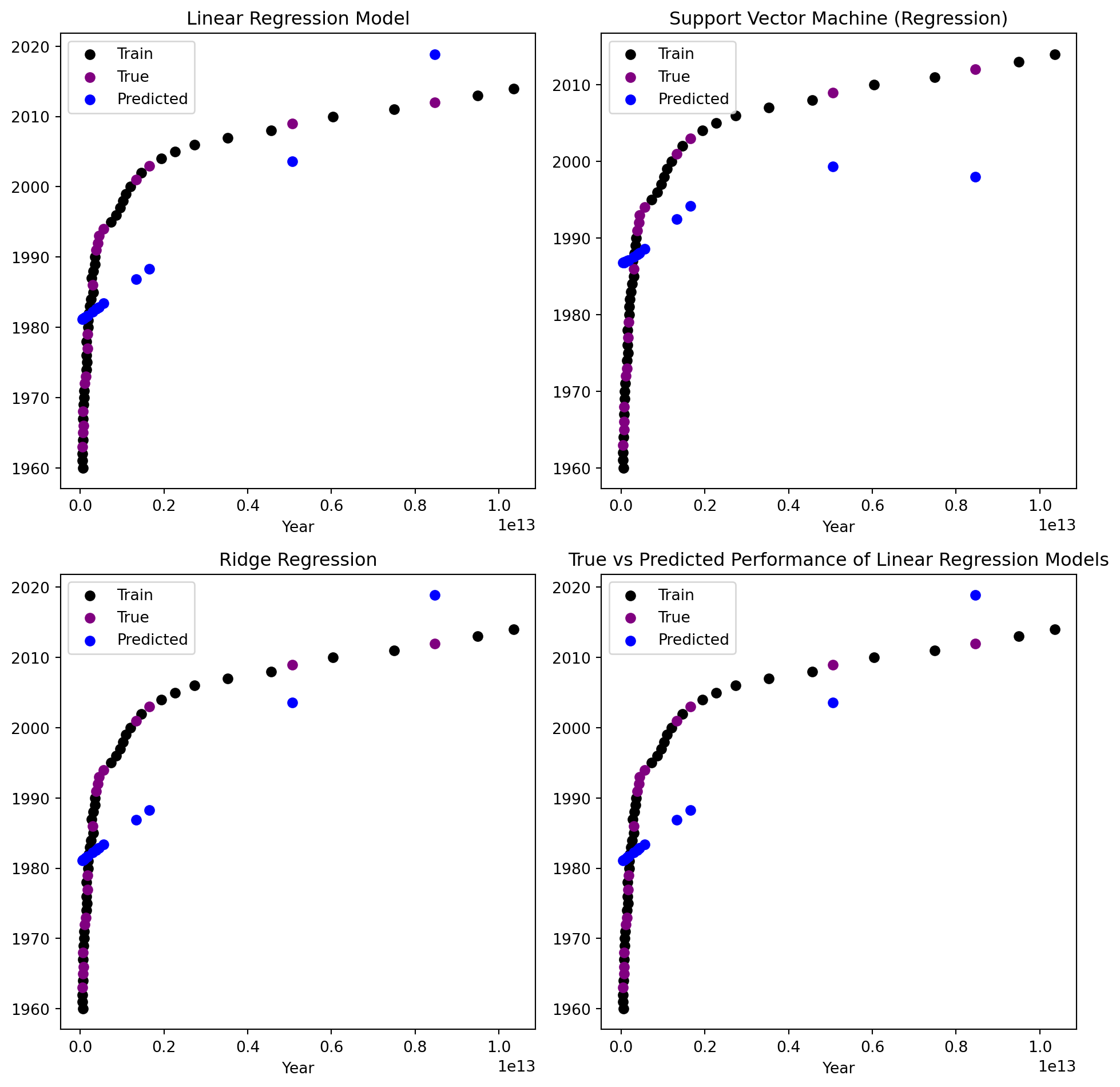
We can plot the training set points as well as the true test set points and predicted test set points for each model (Linear and Non-Linear) to visualize model accuracy and performance. Again, we see that the linear models struggle to accurately predict the target value for a non-linear dataset.
Code
fig, ax = plt.subplots(2,2, figsize=(10, 10));for idx, model inenumerate(models[0:4]): reg = model reg.fit(X_train, y_train) y_pred = reg.predict(X_test)# Plot the data points for training set ax[idx//2][idx%2].scatter(X_train, y_train, marker='o', color='black', label='Train');# Plot the data points for testing set (true) ax[idx//2][idx%2].scatter(X_test, y_test, color='purple', marker='o', label='True');# Plot the data points for testing set (predicted) ax[idx//2][idx%2].scatter(X_test, y_pred, color='blue', marker='o', label='Predicted'); ax[idx//2][idx%2].set_title(model_names[idx]) ax[idx//2][idx%2].set_xlabel("GDP") ax[idx//2][idx%2].set_xlabel("Year") ax[idx//2][idx%2].legend()plt.title("True vs Predicted Performance of Linear Regression Models")plt.show()
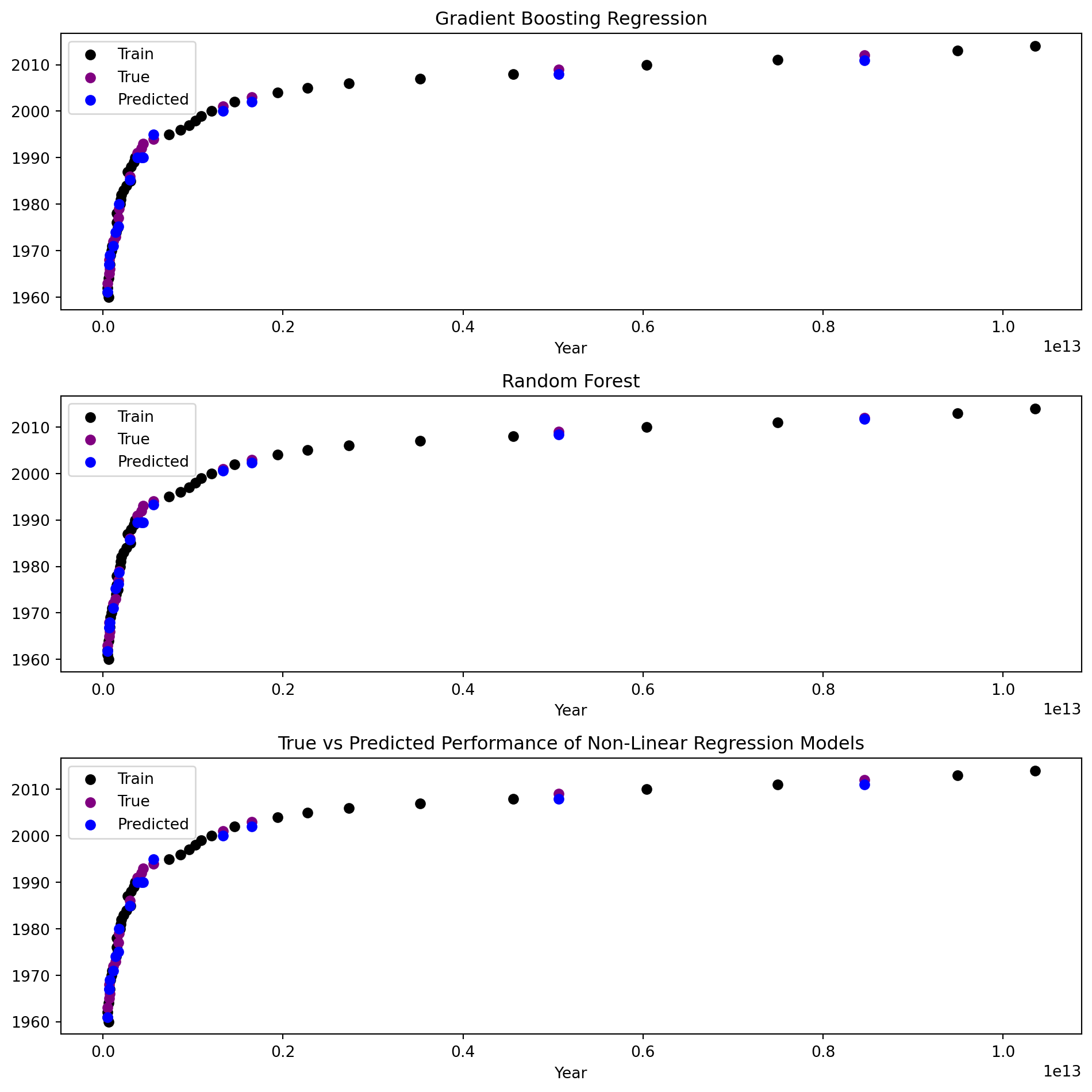
However, the complex, non-linear models are able to capture and analyze the non-linearity and predict the target variable value more accurately.
Code
y_preds = [] # list of model predictionsmodel_scores = [] # list of model scores based on the evaluation metrics definedfig, ax = plt.subplots(3, 1, figsize=(10, 10));for idx, model inenumerate(models[4:]): reg = model reg.fit(X_train, y_train) y_pred = reg.predict(X_test)# Plot the data points for training set ax[idx].scatter(X_train, y_train, marker='o', color='black', label='Train');# Plot the data points for testing set (true) ax[idx].scatter(X_test, y_test, color='purple', marker='o', label='True');# Plot the data points for testing set (predicted) ax[idx].scatter(X_test, y_pred, color='blue', marker='o', label='Predicted'); ax[idx].set_title(model_names[4+idx]) ax[idx].set_xlabel("GDP") ax[idx].set_xlabel("Year") ax[idx].legend() y_preds.append(y_pred) mse = mean_squared_error(y_test.values, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test.values, y_pred) r2 = r2_score(y_test.values, y_pred) evs = explained_variance_score(y_test.values, y_pred) model_scores.append([mse, rmse, mae, r2, evs])plt.title("True vs Predicted Performance of Non-Linear Regression Models")plt.show()
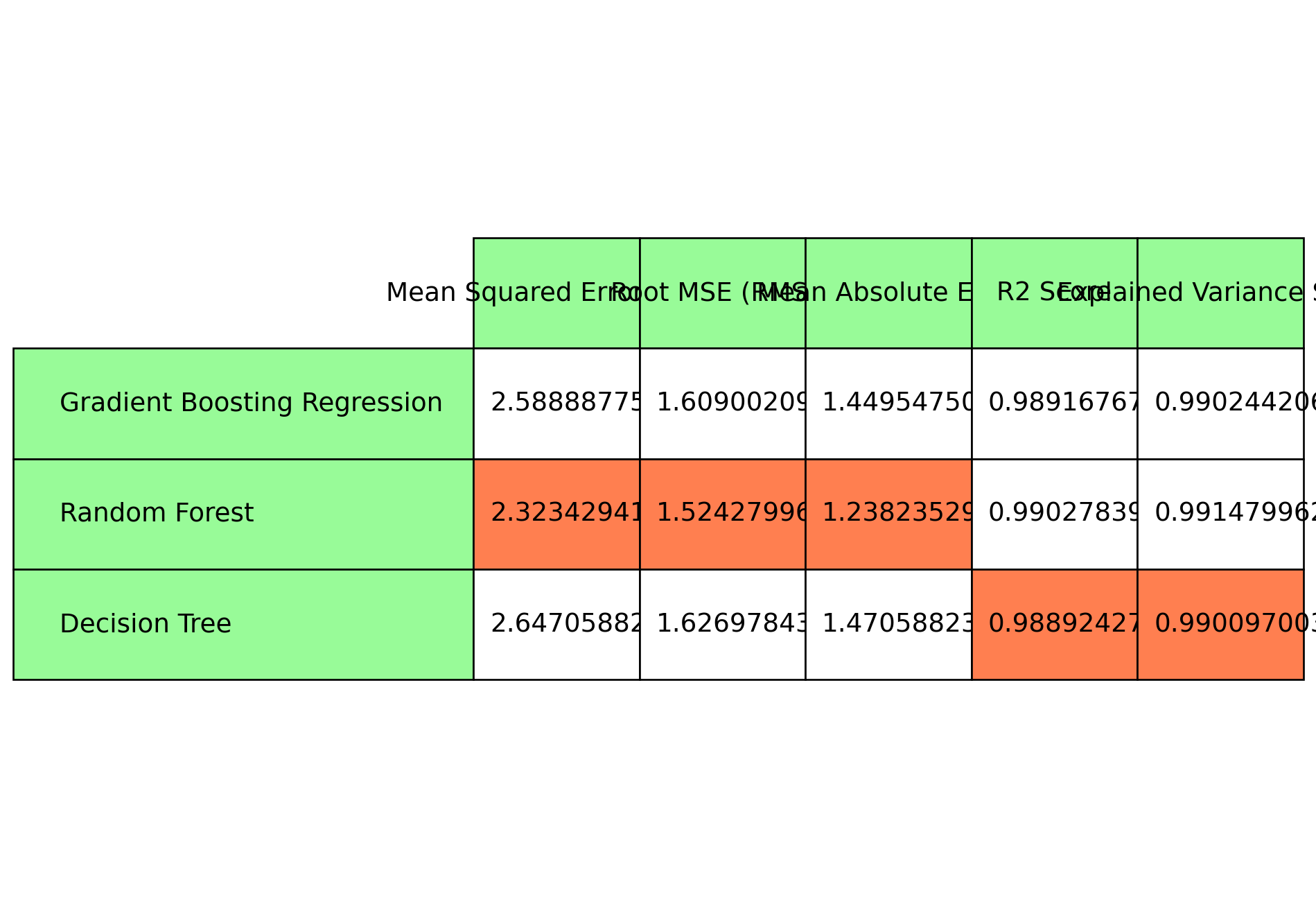
We chart the model performance for the non-linear models. The models used for non-linear regression are Random Forest Regressor, Decision Tree Regressor, and Gradient Boost Regressor.
Code
plt.rcParams["figure.figsize"] = [10, 7]plt.rcParams["figure.autolayout"] =Truefig, axs = plt.subplots(1, 1)axs.axis('tight')axs.axis('off')table1 = axs.table(cellText=model_scores, cellLoc ='left', rowLabels = model_names[4:], rowColours= ["palegreen"] *10, colLabels=evaluation_metrics, colColours= ["palegreen"] *10, loc='center')# Highlight cells with minimum value in each columnfor col_idx, metric inenumerate(evaluation_metrics): col_values = [row[col_idx] for row in model_scores] min_value_idx = col_values.index(min(col_values))# Highlight the cell with minimum value in coral color table1[min_value_idx +1, col_idx].set_facecolor("coral")table1.auto_set_font_size(False)table1.set_fontsize(14)table1.scale(1, 4)fig.tight_layout()plt.show()
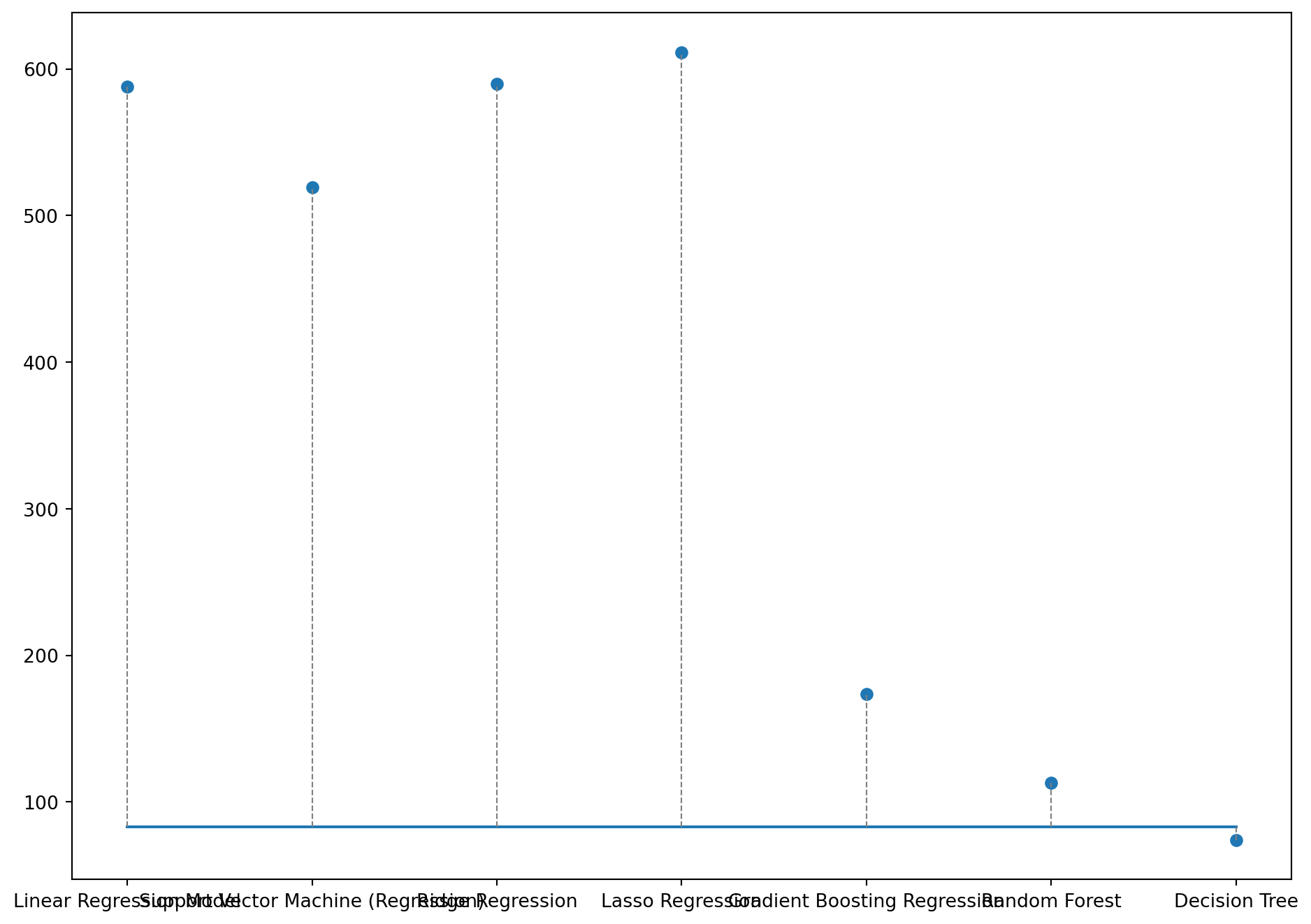
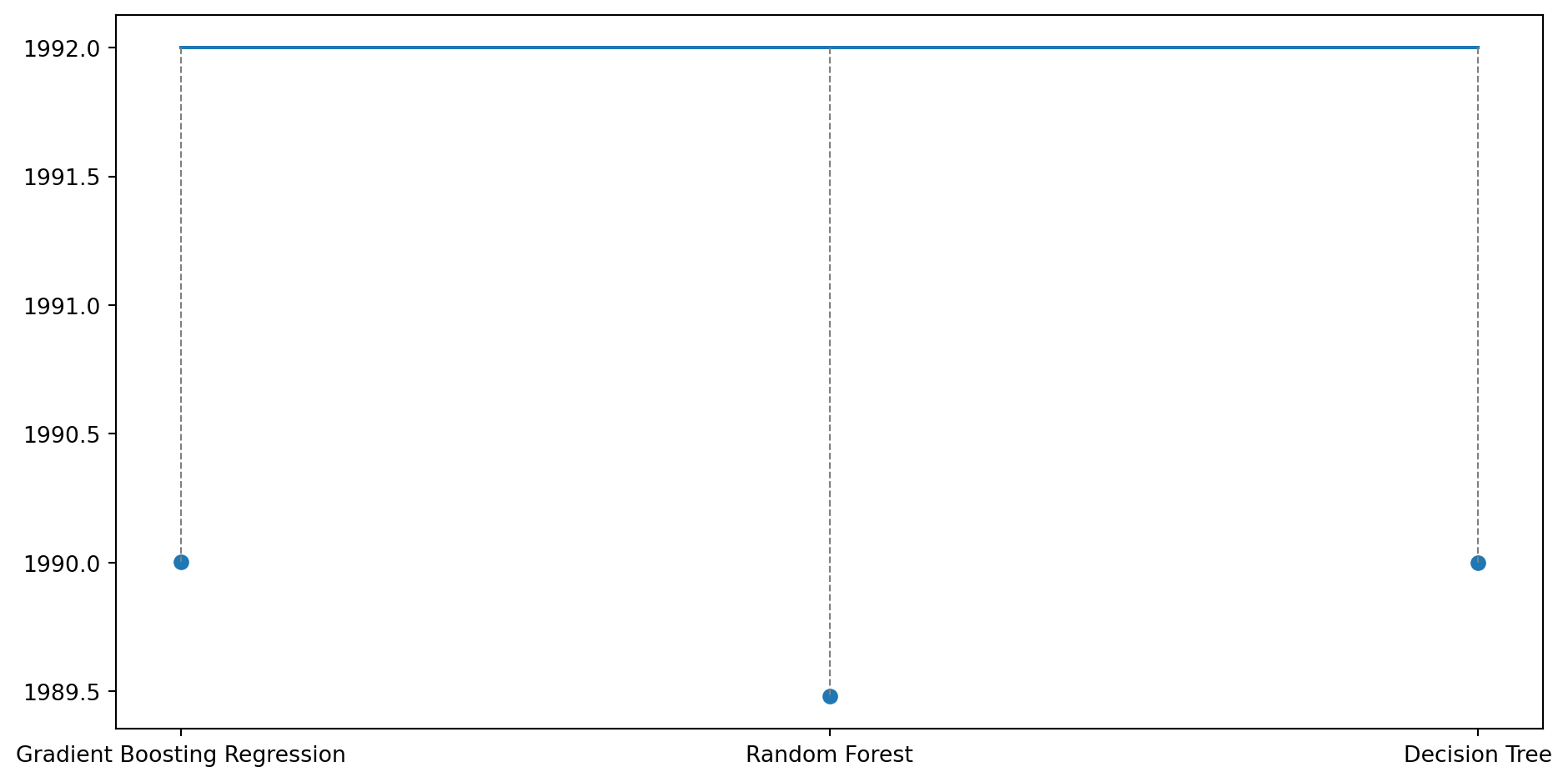
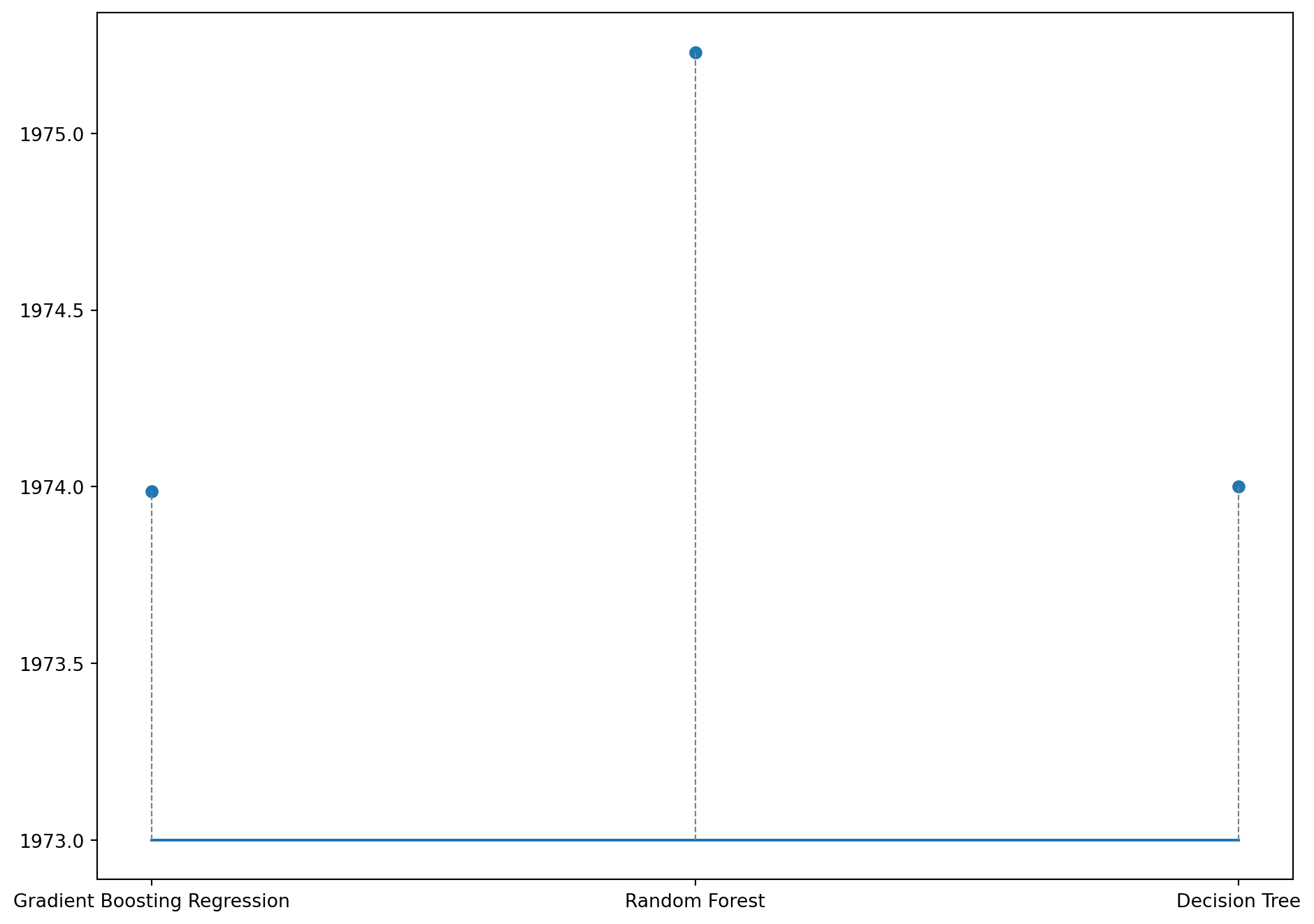
Once again, we analyze the difference between the actual and predicted values for the regression task by each model on 3 randomly chosen data points.
Code
# printing how far the predicted value is to the actual value for a random row in Ximport randomfig, ax = plt.subplots(figsize=(10, 5));length =len(model_names[4:])for i inrange(3): idx = random.randint(0,len(y_test)-1) plt.plot(range(length), [(y_test.values)[idx]]*length, label='True Value'); plt.scatter(range(length), [y_preds[q][idx] for q inrange(length)], label='Predicted Values');for j inrange(length): plt.plot([j, j], [(y_test.values)[idx], y_preds[j][idx]], color='gray', linestyle='--', linewidth=0.8) plt.xticks(range(length), model_names[4:]) plt.tight_layout() plt.show()
From this blog, we get a glimpse into the performance and approach to applying the appropriate based on the type of dataset at hand.
Source Code
---title: "Regression Analysis: Linear Regression and Non-Linear Regression"author: "Anushka S"date: "2023-12-03"categories: [Regression, Machine Learning, Supervised Learning, SVM, Random Forest, Decision Tree, Gradient Boost, Linear, Non-Linear]---[Supervised learning](https://www.ibm.com/topics/supervised-learning#:~:text=Supervised%20learning%2C%20also%20known%20as,data%20or%20predict%20outcomes%20accurately.), also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence. It is defined by its use of labeled datasets to train algorithms that to classify data or predict outcomes accurately.Machine Learning Regression is a technique for investigating the relationship between independent variables or features and a dependent variable or outcome. It’s used as a method for predictive modelling in machine learning, in which an algorithm is used to predict continuous outcomes. You can read more about it [here!](https://www.seldon.io/machine-learning-regression-explained#:~:text=Machine%20Learning%20Regression%20is%20a,used%20to%20predict%20continuous%20outcomes.)In this blog, we will discuss two types of regression problems, Linear Regression, and Non-Linear Regression. For each, we will compare a handful of machine learning models (linear and non-linear models) and present their results on evaluation metrics.**Linear Regression**This form of analysis estimates the coefficients of the linear equation, involving one or more independent variables that best predict the value of the dependent variable. Linear regression fits a straight line or surface that minimizes the discrepancies between predicted and actual output values.We'll make use of the [Seoul Bike Sharing dataset](https://archive.ics.uci.edu/dataset/560/seoul+bike+sharing+demand) which contains count of public bicycles rented per hour in the Seoul Bike Sharing System, with corresponding weather data and holiday information. The dataset contains weather information (Temperature, Humidity, Windspeed, Visibility, Dewpoint, Solar radiation, Snowfall, Rainfall), the number of bikes rented per hour and date information. A sample of the dataset can be seen below. The aim is to predict the bike count required at each hour for the stable supply of rental bikes. ```{python}import pandas as pdimport numpy as npimport warningswarnings.filterwarnings("ignore")df_bike = pd.read_csv("SeoulBikeData.csv")df_bike.head(5)```It is important to check the dataset for any missing values before it is used for model training and testing.```{python}#| echo: falseprint(df_bike.info())#check for count of missing values in each column.print(df_bike.isna().sum())print(df_bike.isnull().sum())```This dataset seems to have no missing values so we're good!Let's format the dataset to ease data processing down the line. Beginning with breaking down the 'Date' into 'Day', 'Month', and 'Year' columns in the dataset.```{python}#| code-fold: false# Can break the date into date, month, year columns and convert them into integers (from strings) for the purpose of correlation mapdays = [int((df_bike['Date'].iloc[i])[0:2]) for i inrange(len(df_bike))]month = [int((df_bike['Date'].iloc[i])[3:5]) for i inrange(len(df_bike))]year = [int((df_bike['Date'].iloc[i])[6:]) for i inrange(len(df_bike))]df_bike['Day'], df_bike['Month'], df_bike['Year'] = days, month, yeardf_bike.head(5)```Next, we convert string values such as the values in the 'Seasons', 'Functioning Day', and 'Holiday' columns. We are able to do this by mapping the discrete set of string values to a discrete set of integer values.```{python}#| code-fold: falsedf1_bike = df_bike.drop(columns = ['Date'])# map unique season to numbers, map holiday to binary, and functioning day to binaryseasons = {}for idx, i inenumerate(df_bike['Seasons'].drop_duplicates()): seasons[i] = idxholiday = {"No Holiday": 0, "Holiday": 1}functioning = {"Yes": 0, "No": 1}df1_bike.Holiday = [holiday[item] for item in df_bike.Holiday]df1_bike.Seasons = [seasons[item] for item in df_bike.Seasons]df1_bike['Functioning Day'] = [functioning[item] for item in df1_bike['Functioning Day'] ]df1_bike.head(3)```Plotting the correlation matrix to identify the relationship, and the strength of relationship between the features(variables) in the dataset and also understand how strongly they are correlated with the target variable which is the rented bike count.```{python}import seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize=(10, 8))corr = df1_bike.corr()sns.heatmap(corr, cmap=sns.diverging_palette(220, 10, as_cmap=True), vmin=-1.0, vmax=1.0, square=True, ax=ax)```Below, we can plot visualizations to see how each feature (variable) effects the target: Rented Bike Count.```{python}plt.rcParams["figure.autolayout"] =Truefig, ax = plt.subplots(2, 2, figsize=(10, 8));# hour vs bike countsns.barplot(data=df1_bike,x='Hour',y='Rented Bike Count',ax=ax[0][0], palette='viridis');ax[0][0].set(title='Count of Rented bikes acording to Hour');# Functioning vs bike countsns.barplot(data=df1_bike,x='Functioning Day',y='Rented Bike Count',ax=ax[0][1], palette='inferno');ax[0][1].set(title='Count of Rented bikes acording to Functioning Day');ax[0][1].set_xticklabels(['Yes', 'No'])# season vs bike countsns.barplot(data=df1_bike,x='Seasons', y='Rented Bike Count',ax=ax[1][0], palette='plasma');ax[1][0].set(title='Count of Rented bikes acording to Seasons');ax[1][0].set_xticklabels(['Winter', 'Spring', 'Summer', 'Autumn'])# month vs bike countsns.barplot(data=df1_bike,x='Month',y='Rented Bike Count',ax=ax[1][1], palette='cividis');ax[1][1].set(title='Count of Rented bikes acording to Month ');plt.show()``````{python}fig,ax=plt.subplots(figsize=(10,8))sns.pointplot(data=df1_bike,x='Hour',y='Rented Bike Count',hue='Seasons',ax=ax);ax.set(title='Count of Rented bikes acording to seasons and hour of the day');``````{python}fig, ax = plt.subplots(figsize=(10, 8));# temperature vs bike count# Convert temperature in groups of 5C and average the rented bike counts for that range (rounding to 5s)temp_min, temp_max =round(min(df1_bike['Temperature(C)'])/5)*5, round(max(df1_bike['Temperature(C)'])/5)*5dict_temp = {}for i inrange(temp_min, temp_max, 5):# Filter rows based on the temperature interval filtered_df = df1_bike[(df1_bike['Temperature(C)'] >= i) & (df1_bike['Temperature(C)'] < i+5)] dict_temp[i] = filtered_df['Rented Bike Count'].mean()# print(dict_temp)# print(temp_max, temp_min)sns.barplot(data=dict_temp,ax=ax, palette='plasma');ax.set(title='Count of Rented bikes acording to Temperature');# plt.show()```Printing the regression plot (Dependent Features vs Target Varibale).```{python}#| code-fold: falsefig,ax=plt.subplots(4, 4, figsize=(10,10)) # since we know there are 16 featuresfor idx, col inenumerate(df1_bike.columns): sns.regplot(x=df1_bike[col],y=df1_bike['Rented Bike Count'],scatter_kws={"color": 'blue'}, line_kws={"color": "black"}, ax=ax[idx//4][idx%4])```To train and evaluate the machine learning models we need to split the dataset appropriately into the training and testing datasets.Hence, we perform an 80-20 train-test split here.```{python}from sklearn.model_selection import train_test_splity = df1_bike['Rented Bike Count']X = (df1_bike.drop(columns = ['Rented Bike Count'])).to_numpy()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)```The following are the models used for estimating the number of bikes rented given other data.The code implementations for each can be found in the scikit-learn library (linked for each model), and the model paramters used are default parameters.1. *Linear regression model*[Linear regression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html) is a simple yet powerful algorithm that models the relationship between the input features and the target variable by fitting a linear equation to the observed data. The main algorithm involves finding the coefficients that minimize the sum of squared differences between the predicted and actual values. This is typically achieved using the Ordinary Least Squares (OLS) method, aiming to optimize the line's parameters to best represent the data points.2. *Support Vector Machine (Regressor)*In regression tasks, [Support Vector Machines](https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVR.html#sklearn.svm.SVR) (SVM) aim to find the hyperplane that best represents the relationship between the input features and the target variable. The primary algorithm involves identifying the support vectors and determining the optimal hyperplane to maximize the margin while minimizing the error. SVM uses a loss function that penalizes deviations from the regression line, and the algorithm seeks to find the coefficients that minimize this loss.3. *Ridge Regression*[Ridge Regression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html#sklearn.linear_model.Ridge) is an extension of linear regression that introduces a regularization term to prevent overfitting. The main algorithm involves adding a penalty term to the linear regression objective function, which is proportional to the square of the L2 norm of the coefficients. This regularization term helps stabilize the model by shrinking the coefficients, particularly useful when dealing with multicollinearity.4. *Lasso Regression*[Lasso Regression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html#sklearn.linear_model.Lasso), similar to Ridge Regression, introduces regularization to linear regression. The main algorithm incorporates a penalty term, but in this case, it is proportional to the absolute value of the L1 norm of the coefficients. Lasso regression is effective for feature selection as it tends to produce sparse coefficient vectors, driving some coefficients to exactly zero.5. *Gradient Boosting Regressor*[Gradient Boosting Regressor](https://scikit-learn.org/stable/auto_examples/ensemble/plot_gradient_boosting_regression.html) is an ensemble learning method that builds a series of decision trees sequentially. The main algorithm involves fitting a weak learner (usually a shallow decision tree) to the residuals of the previous trees. The predictions of individual trees are combined to improve overall accuracy. The algorithm minimizes a loss function by adjusting the weights of the weak learners.6. *Random Forest Regressor*[Random Forest Regressor](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html) is an ensemble learning method that constructs multiple decision trees during training. The main algorithm involves training each tree on a random subset of the training data and features. The predictions of individual trees are then averaged or aggregated to reduce overfitting and improve generalization. Random Forest leverages the diversity among trees for robust predictions.7. *Decision Tree Regressor*[Decision Tree Regressor](https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html#sklearn.tree.DecisionTreeRegressor) models the relationship between input features and the target variable by recursively splitting the data based on feature thresholds. The main algorithm involves selecting the best split at each node to minimize the variance of the target variable. Decision trees are constructed until a stopping criterion is met, creating a tree structure that facilitates predictive modeling.```{python}#| code-fold: falsefrom sklearn.linear_model import LinearRegressionfrom sklearn.svm import SVRfrom sklearn import linear_modelfrom sklearn.ensemble import GradientBoostingRegressorfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.tree import DecisionTreeRegressorfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, explained_variance_scoremodel_names = ['Linear Regression Model','Support Vector Machine (Regression)','Ridge Regression','Lasso Regression','Gradient Boosting Regression','Random Forest','Decision Tree']models = [LinearRegression(), SVR(), linear_model.Ridge(), linear_model.Lasso(), GradientBoostingRegressor(), RandomForestRegressor(), DecisionTreeRegressor()]evaluation_metrics = ['Mean Squared Error (MSE)','Root MSE (RMSE)','Mean Absolute Error','R2 Score', 'Explained Variance Score']```The model is fit on the training data, and predicted for the testing data. Regression models are commonly evaluated on the following metrics:1. *Mean Squared Error (MSE)*: MSE calculates the average squared difference between the predicted and actual values, providing a measure of the model's precision.$ \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2$2. *Root Mean Squared Error (RMSE)*: RMSE is the square root of MSE and represents the average magnitude of the residuals in the same units as the target variable.$ \text{RMSE} = \sqrt{\text{MSE}}$3. *Mean Absolute Error (MAE)*: MAE calculates the average absolute difference between the predicted and actual values, providing a measure of the model's accuracy.$ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|$4. *R2 Score*: R2 Score, or the coefficient of determination, measures the proportion of the variance in the dependent variable that is predictable from the independent variables.$ R^2 = 1 - \frac{\text{SSR}}{\text{SST}} where \text{SSR} is the sum of squared residuals, and \text{SST} is the total sum of squares.$5. *Explained Variance Score*: The Explained Variance Score measures the proportion by which the model's variance is reduced compared to a simple mean baseline.$ \text{Explained Variance} = 1 - \frac{\text{Var}(y - \hat{y})}{\text{Var}(y)} where where y is the actual values and \hat{y} is the predicted values$```{python}#| code-fold: falsey_preds = [] # list of model predictionsmodel_scores = [] # list of model scores based on the evaluation metrics definedfor model in models: reg = model reg.fit(X_train, y_train) y_pred = reg.predict(X_test) y_preds.append(y_pred) mse = mean_squared_error(y_test.values, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test.values, y_pred) r2 = r2_score(y_test.values, y_pred) evs = explained_variance_score(y_test.values, y_pred) model_scores.append([mse, rmse, mae, r2, evs])```Let us visualize the outputs of the linear models 'Linear Regression Model','Support Vector Machine (Regression)','Ridge Regression', and 'Lasso Regression'. and evaluate the results.```{python}plt.rcParams["figure.figsize"] = [10,7]plt.rcParams["figure.autolayout"] =Truefig, axs = plt.subplots(1, 1)axs.axis('tight')axs.axis('off')table1 = axs.table(cellText=model_scores[0:4], cellLoc ='left', rowLabels = model_names[0:4], rowColours= ["palegreen"] *10, colLabels=evaluation_metrics, colColours= ["palegreen"] *10, loc='center')# Highlight cells with minimum value in each columnfor col_idx, metric inenumerate(evaluation_metrics): col_values = [row[col_idx] for row in model_scores[0:4]] min_value_idx = col_values.index(min(col_values))# Highlight the cell with minimum value in coral color table1[min_value_idx +1, col_idx].set_facecolor("coral")table1.auto_set_font_size(False)table1.set_fontsize(14)table1.scale(1, 4)fig.tight_layout()plt.show()```Now, let us compare the performance of the linear models against non linear models on Linear Regression.```{python}plt.rcParams["figure.figsize"] = [10, 7]plt.rcParams["figure.autolayout"] =Truefig, axs = plt.subplots(1, 1)axs.axis('tight')axs.axis('off')table2 = axs.table(cellText=model_scores, cellLoc ='left', rowLabels = model_names, rowColours= ["palegreen"] *10, colLabels=evaluation_metrics, colColours= ["palegreen"] *10, loc='center')# Highlight cells with minimum value in each columnfor col_idx, metric inenumerate(evaluation_metrics): col_values = [row[col_idx] for row in model_scores] min_value_idx = col_values.index(min(col_values))# Highlight the cell with minimum value in coral color table2[min_value_idx +1, col_idx].set_facecolor("coral")table2.auto_set_font_size(False)table2.set_fontsize(14)table2.scale(1, 4)fig.tight_layout()plt.show()```As we can see, non-linear models, due to their complex structure and abilty to map and analyze/learn from complex data, perform better on this task. However, it is not always that non-linear models are better than linear models since we must keep in mind the computational expense and efficiency of a model for a task, as well as the [bias-variance](https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote12.html) tradeoff which again, is dependent not only on the model but also on the dataset/application at hand.Analysing the difference between the actual and predicted values for the regression task by each model on 3 randomly chosen data points.```{python}# printing how far the predicted value is to the actual value for a random row in Ximport randomfig, ax = plt.subplots(figsize=(10, 5));length =len(model_names)for i inrange(3): idx = random.randint(0,len(y_test)-1) plt.plot(range(length), [(y_test.values)[idx]]*length, label='True Value'); plt.scatter(range(length), [y_preds[q][idx] for q inrange(length)], label='Predicted Values');for j inrange(length): plt.plot([j, j], [(y_test.values)[idx], y_preds[j][idx]], color='gray', linestyle='--', linewidth=0.8) plt.xticks(range(length), model_names) plt.tight_layout() plt.show()```**Non Linear Regression**[Nonlinear regression](https://www.mathworks.com/discovery/nonlinear-regression.html) is a statistical technique that helps describe nonlinear relationships in experimental data. Nonlinear regression models are generally assumed to be parametric, where the model is described as a nonlinear equation. Typically machine learning methods are used for non-parametric nonlinear regression.Parametric nonlinear regression models the dependent variable (also called the response) as a function of a combination of nonlinear parameters and one or more independent variables (called predictors). The model can be univariate (single response variable) or multivariate (multiple response variables).The parameters can take the form of an exponential, trigonometric, power, or any other nonlinear function. The non-linear [dataset](https://github.com/Lawrence-Krukrubo) models China's GDP value for each year from 1960-2014. A sample of the dataset and the dataset visualization can be seen below.```{python}df_gdp = pd.read_csv("China_GDP.csv")print(df_gdp.info())print(df_gdp.isna().sum())df_gdp.head(5)``````{python}#| code-fold: false# plot Year vs GDP_valuesns.scatterplot(data=df_gdp, x ='Value', y ='Year');plt.show()```We try to apply a regression line plot for the data. We see that the regression line is not able to accurately capture a linear relationship due to the non-linear relationship between the variables.```{python}#| code-fold: false# Regression line plotsns.regplot(x=df_gdp['Value'],y=df_gdp['Year'],scatter_kws={"color": 'blue'}, line_kws={"color": "black"})plt.show()```Splitting the dataset into 80-20 training-testing set to train and evaluate the aforementioned models. ```{python}from sklearn.model_selection import train_test_splity = df_gdp['Year']X = (df_gdp.drop(columns = ['Year'])).to_numpy()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)```We can plot the training set points as well as the true test set points and predicted test set points for each model (Linear and Non-Linear) to visualize model accuracy and performance. Again, we see that the linear models struggle to accurately predict the target value for a non-linear dataset.```{python}fig, ax = plt.subplots(2,2, figsize=(10, 10));for idx, model inenumerate(models[0:4]): reg = model reg.fit(X_train, y_train) y_pred = reg.predict(X_test)# Plot the data points for training set ax[idx//2][idx%2].scatter(X_train, y_train, marker='o', color='black', label='Train');# Plot the data points for testing set (true) ax[idx//2][idx%2].scatter(X_test, y_test, color='purple', marker='o', label='True');# Plot the data points for testing set (predicted) ax[idx//2][idx%2].scatter(X_test, y_pred, color='blue', marker='o', label='Predicted'); ax[idx//2][idx%2].set_title(model_names[idx]) ax[idx//2][idx%2].set_xlabel("GDP") ax[idx//2][idx%2].set_xlabel("Year") ax[idx//2][idx%2].legend()plt.title("True vs Predicted Performance of Linear Regression Models")plt.show()```However, the complex, non-linear models are able to capture and analyze the non-linearity and predict the target variable value more accurately.```{python}y_preds = [] # list of model predictionsmodel_scores = [] # list of model scores based on the evaluation metrics definedfig, ax = plt.subplots(3, 1, figsize=(10, 10));for idx, model inenumerate(models[4:]): reg = model reg.fit(X_train, y_train) y_pred = reg.predict(X_test)# Plot the data points for training set ax[idx].scatter(X_train, y_train, marker='o', color='black', label='Train');# Plot the data points for testing set (true) ax[idx].scatter(X_test, y_test, color='purple', marker='o', label='True');# Plot the data points for testing set (predicted) ax[idx].scatter(X_test, y_pred, color='blue', marker='o', label='Predicted'); ax[idx].set_title(model_names[4+idx]) ax[idx].set_xlabel("GDP") ax[idx].set_xlabel("Year") ax[idx].legend() y_preds.append(y_pred) mse = mean_squared_error(y_test.values, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test.values, y_pred) r2 = r2_score(y_test.values, y_pred) evs = explained_variance_score(y_test.values, y_pred) model_scores.append([mse, rmse, mae, r2, evs])plt.title("True vs Predicted Performance of Non-Linear Regression Models")plt.show()```We chart the model performance for the non-linear models. The models used for non-linear regression are *Random Forest Regressor*, *Decision Tree Regressor*, and *Gradient Boost Regressor*.```{python}plt.rcParams["figure.figsize"] = [10, 7]plt.rcParams["figure.autolayout"] =Truefig, axs = plt.subplots(1, 1)axs.axis('tight')axs.axis('off')table1 = axs.table(cellText=model_scores, cellLoc ='left', rowLabels = model_names[4:], rowColours= ["palegreen"] *10, colLabels=evaluation_metrics, colColours= ["palegreen"] *10, loc='center')# Highlight cells with minimum value in each columnfor col_idx, metric inenumerate(evaluation_metrics): col_values = [row[col_idx] for row in model_scores] min_value_idx = col_values.index(min(col_values))# Highlight the cell with minimum value in coral color table1[min_value_idx +1, col_idx].set_facecolor("coral")table1.auto_set_font_size(False)table1.set_fontsize(14)table1.scale(1, 4)fig.tight_layout()plt.show()```Once again, we analyze the difference between the actual and predicted values for the regression task by each model on 3 randomly chosen data points.```{python}# printing how far the predicted value is to the actual value for a random row in Ximport randomfig, ax = plt.subplots(figsize=(10, 5));length =len(model_names[4:])for i inrange(3): idx = random.randint(0,len(y_test)-1) plt.plot(range(length), [(y_test.values)[idx]]*length, label='True Value'); plt.scatter(range(length), [y_preds[q][idx] for q inrange(length)], label='Predicted Values');for j inrange(length): plt.plot([j, j], [(y_test.values)[idx], y_preds[j][idx]], color='gray', linestyle='--', linewidth=0.8) plt.xticks(range(length), model_names[4:]) plt.tight_layout() plt.show()```From this blog, we get a glimpse into the performance and approach to applying the appropriate based on the type of dataset at hand.